










Briefing
Most AI assistants forget you the moment a conversation ends. The next time you open the app, you start from scratch, re-explaining who's on the project, what was decided last week, and where that file lives. OpenHuman, an open-source desktop assistant, is built around the opposite idea: an AI that holds a running picture of your work and the people in it.
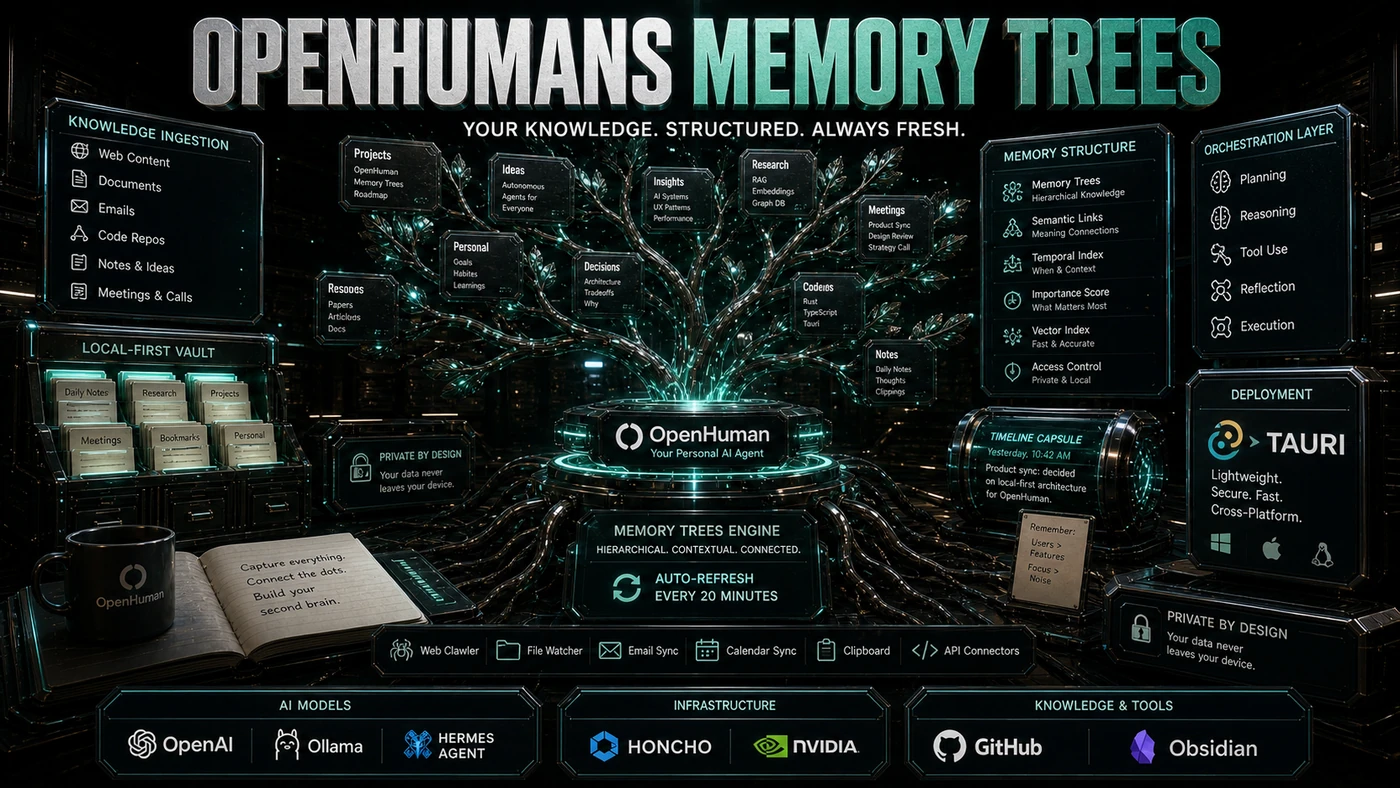
The piece doing the heavy lifting is a feature called Memory Trees. Instead of dumping your documents into a pile and fishing out whatever looks similar to your question, it keeps track of how things connect, which email belongs to which project, who's involved, what deadline is looming. And it does all of this on your own machine, with nothing shipped to a cloud server.
For a business team, the practical promise is simple: ask "what's the status of the Alpha project?" and get an answer that pulls from emails, chat, files, and meeting notes at once, rather than a single stray document. Whether the architecture lives up to that in daily use is the real test, but the design is a clear bet against the way most AI memory works today.
Here's how it actually works under the hood.
The Problem with Flat Memory
Most AI assistants use vector databases for memory. Documents get chunked, embedded, and stored as vectors. Retrieval happens by semantic similarity, find the chunks closest to your query. That's fine for simple lookups, but it falls apart on relationships.
Say you're working on a project called "Alpha." Flat memory might store:
- "Alpha project requirements document"
- "Email from John about Alpha timeline"
- "Slack message in #alpha about API design"
- "Meeting notes from Alpha kickoff"
What it misses is that these are all connected, same project, same people, same deadlines. Memory Trees are built to capture exactly that.
Hierarchical Organisation
Memory Trees organise information as a tree structure with multiple levels:
Root: The user, everything connects back here.
Projects: Top-level containers for work streams. "Alpha," "Personal," "Learning."
Entities: People, organisations, and concepts that show up across contexts. "John Smith," "OpenAI API," "Q3 Goals."
Documents: Specific files, emails, messages. The leaf nodes of the tree.
Relationships: Edges connecting nodes, "John is on the Alpha project," "this email references the API design document."
A note on accuracy here: this Root/Projects/Entities/Documents framing is a simplified way to picture it. OpenHuman's own documentation describes the real architecture as three tiers, Source Trees, Topic Trees, and a Global Tree, with an L0 buffer that seals into L1 summaries as it fills. The mental model above is useful for understanding the idea; the engineering is a summary cascade rather than a literal graph of named edges.
Either way, the behaviour is the part that matters. Ask "what's the status of the Alpha project?" and OpenHuman walks the tree: Alpha → related documents → recent emails → people involved → upcoming deadlines. Then it stitches that into one coherent answer.
Auto-Fetch: Keeping Current
Memory Trees [auto-fetch updates every 20 minutes](https://tinyhumans.gitbook.io/openhuman). In practice:
- New emails land in the relevant project context
- File changes show up in the document nodes
- Calendar updates adjust the timeline picture
- Slack messages fill out conversation threads
Twenty minutes is the balance point between staying current and hammering your machine. Background indexing leans on local processing, which keeps it workable on laptops and older hardware. The docs confirm a battery-aware scheduler that throttles this background work when you're unplugged; one reportedly stretches the interval out to around 60 minutes on battery, though that exact figure isn't confirmed in OpenHuman's official materials.
Technical Implementation
The Memory Trees system breaks down into a few parts:
Ingestion Pipeline: Connects to 118+ integrations, normalising data from all those sources into a common format.
Relationship Extractor: Reads content to find connections. When an email mentions a file and a person, it wires up edges between all three.
Tree Builder: Keeps the hierarchy intact, resolving conflicts and merging duplicate entities along the way.
Query Engine: Walks the tree to answer questions, mixing traversal with LLM-based synthesis.
Embedding Store: Supplementary vector storage for semantic search inside the tree.
Privacy by Design
All Memory Tree data stays local on your machine, stored in a SQLite database plus an Obsidian-compatible Markdown vault under your home folder. No cloud sync, no telemetry, no external access. The project is released under GPLv3. Worth being precise about what that license actually does, though: GPLv3's copyleft applies to distributed derivative works, not to network or hosted use, that's the domain of AGPL. So while the license keeps modified copies open, it wouldn't by itself force a SaaS operator running the code to publish their changes.
For backup, Memory Trees export to encrypted local files. For syncing across devices, you set up your own encrypted sync, rsync, Syncthing, whatever you prefer.
CPU-Only Inference
One of the design choices is running indexing without a GPU. That brings some real advantages:
- No GPU required
- Works on older hardware
- Lower power draw
- No dependency on NVIDIA drivers
To be accurate, "CPU-only" overstates it slightly. Local inference is optional, OpenHuman routes it through Ollama or LM Studio (for example, a small Gemma3 model that runs on most laptops without a GPU), and where a GPU is available, those tools can use it. Low-level tasks like summarization run locally either way. The trade-off is slower indexing, but the 20-minute interval makes that easy to live with. Query-time inference can lean on a GPU when you want faster responses.
Comparison with Other Systems
vs Vector DBs: Memory Trees keep the relationships that flat vectors throw away. The tree structure makes contextual answers possible where plain semantic search can't.
vs Graph RAG: Same family, both use graph structures, but Memory Trees are tuned for personal knowledge, with relationship extraction happening automatically.
vs Honcho (Hermes): This one is more of an editorial read than an established fact; OpenHuman's own materials don't spell out the relationship. The rough idea is that Honcho leans toward user modelling and dialectic memory while Memory Trees focus on organising information and preserving relationships, which would make them complementary. Treat that as an unconfirmed comparison rather than a documented integration.
Real-World Impact
Users say Memory Trees change the way they work:
- Project context: "What did we decide about the API last week?" returns an answer drawn from several sources at once.
- People awareness: "When did I last talk to John?" pulls up emails, Slack messages, and meeting notes in order.
- Document discovery: "Find that spreadsheet with the Q3 numbers" tracks down the file even when you've forgotten what it was called.
OpenHuman's momentum on GitHub, tens of thousands of stars and climbing, points to a real appetite for AI that knows your actual context, not just your last few messages. Memory Trees are the bet on how to deliver that while keeping everything private and local.