

The News: Export Restrictions Are Lifted
The Claude Fable 5 story has flipped. Anthropic said the US government applied export controls to Claude Fable 5 and Claude Mythos 5 on June 12, 2026, forcing the company to suspend access while it worked through nationality verification and rule clarity. On June 30, 2026, Anthropic said the US Department of Commerce had lifted those controls and that Fable 5 would become available globally from Wednesday, July 1, 2026 on Claude Platform, Claude.ai, Claude Code, and Claude Cowork.
That matters because Fable 5 had become more than a model name. It was the model builders were testing for the hard layer of AI work: ambitious code, multi-step planning, long-context research, UI generation, game prototypes, and agentic workflows that need to hold intent for more than a few chat turns. In a 1 July 2026 Universe of AI briefing, that access shift was the lead: not another rumour, but a return window.

The right reaction is disciplined excitement. Fable 5 returning is good news for builders, but the interruption also reminded everyone that model access is operational infrastructure. A business should be excited to test the model and cautious enough to keep routing, review, and fallback paths in place.
Why This Return Feels Bigger Than A Model Update
Normal model updates create a few benchmark charts and a week of prompt screenshots. Fable 5 created something sharper: a short-lived glimpse of a model that many creators described as a meaningful jump in general work capacity, followed by a shutdown that made the whole market pay attention.
The return therefore lands in two registers at once. It is exciting because builders may regain a powerful model. It is sobering because the interruption proved that serious AI teams need routing, fallback models, and test suites. A model can be brilliant and still not be something you build your entire operating system around without a resilience plan.
For AI Kick Start readers, that is the practical frame. Do not ask only whether Fable 5 is impressive. Ask where it reduces friction without creating a larger governance, security, cost, or continuity problem.
The Recap: What Fable 5 Was Before The Shutdown
The pre-shutdown story starts on June 9, 2026, when Anthropic positioned Claude Fable 5 as a public model built from the more capable Mythos line. In the official launch video and launch post, the pitch was clear: this was not just another assistant for short answers. It was a model for ambitious work, with stronger long-horizon reasoning and safety systems designed to make a more capable class usable by the public.
The official framing also explained why the model was sensitive. Anthropic described prior Mythos-style capabilities as strong enough to surface thousands of cybersecurity vulnerabilities, which meant public access required safeguards. Fable 5 was presented as the public version that could route high-risk areas, including cybersecurity and biology, into safer paths while still giving users a more capable general model.
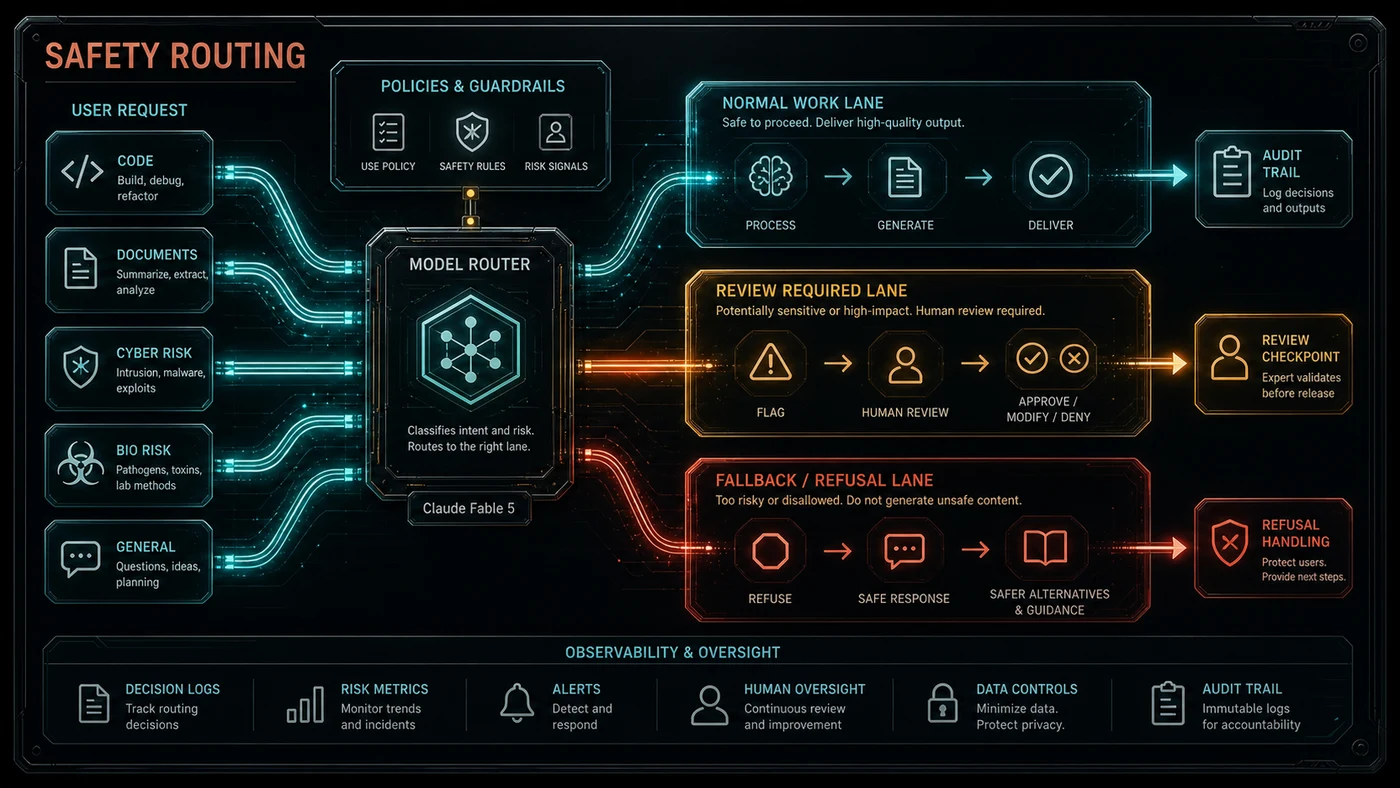
That is the core tension of Fable 5. The model is compelling because it is stronger. It is sensitive because stronger models can do more in every direction. The return should be celebrated, but mature teams should treat it as a capability launch and a control-system moment at the same time.
What Anthropic Says Teams Get Back
Anthropic's launch and platform documentation describe Fable 5 as a high-capability model for demanding reasoning and long-horizon agentic work. The Claude Platform docs list the API model ID as claude-fable-5, a 1M-token context window by default, up to 128k output tokens per request, and launch pricing of $10 per million input tokens and $50 per million output tokens. Pricing and availability can change, so teams should verify current terms before committing budget.
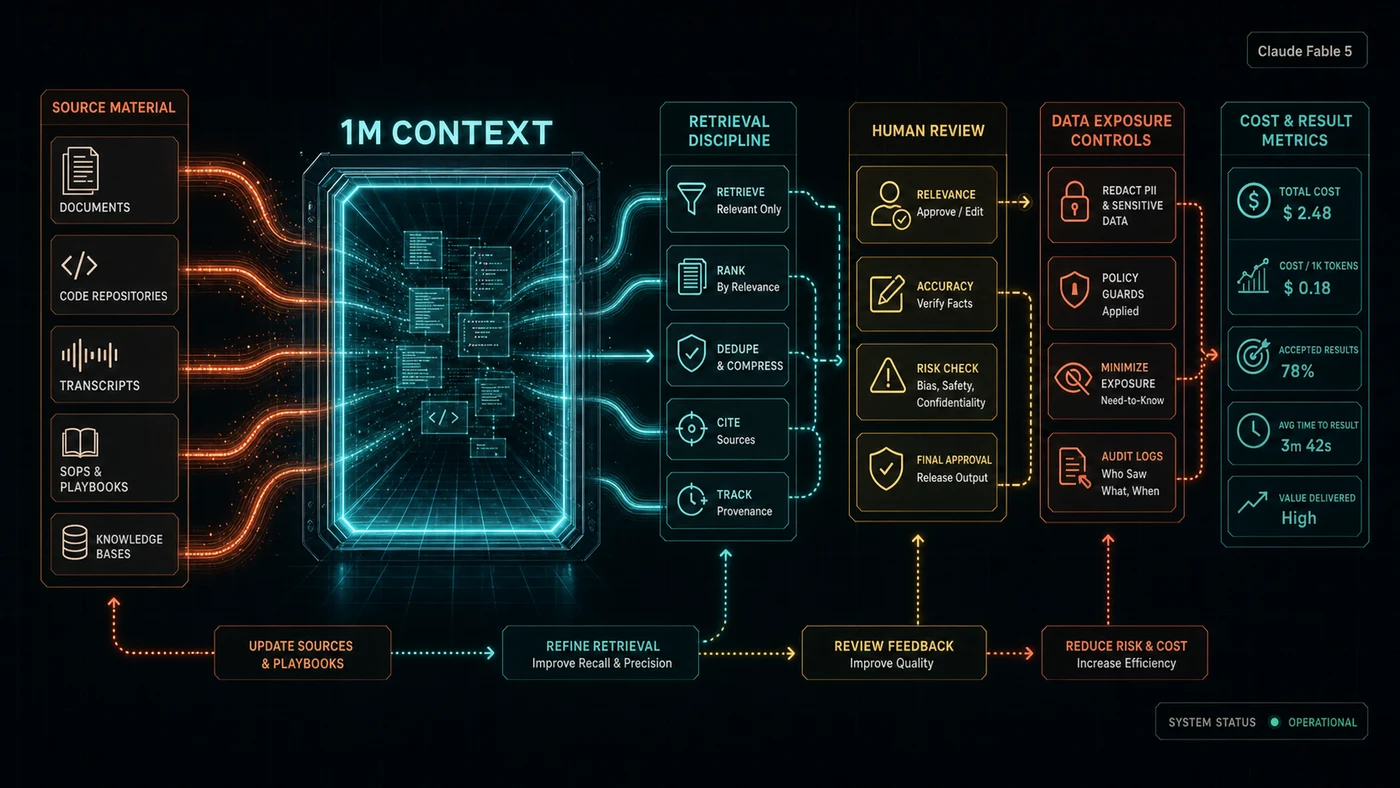
| Area | Official signal | Practical interpretation |
|---|---|---|
| Model ID | claude-fable-5 | Update configs deliberately and keep old routes available until the test set proves the switch. |
| Context | 1M-token default context window | Useful for full documents, repos, transcripts, and SOPs, but still needs retrieval discipline and budget limits. |
| Output | Up to 128k output tokens | Good for long drafts and generated artefacts, but review time becomes part of the cost. |
| Pricing | $10/$50 per million input/output tokens at launch | Fable 5 should be routed to work where quality justifies the spend. |
| Retention | 30-day retention listed in docs | Sensitive customer workloads need a data-classification decision before use. |
| Refusals | API refusals may return HTTP 200 with stop_reason: "refusal" | Production code must handle refusal as a successful response that still needs a fallback path. |
That launch promise is why the return is not just a consumer chatbot story. If Fable 5 can reliably hold more context, plan more deeply, and use tools without losing the thread, it belongs in the business workflows where quality compounds: codebase refactors, policy reviews, document-heavy customer operations, research dashboards, strategy memos, and multi-agent build pipelines.
The Creator Tests That Made Builders Pay Attention
The public excitement came from what happened after launch. Creator tests did what official marketing cannot do: they took the model into messy prompts, visual work, one-shot builds, and head-to-head comparisons.
tef pushed the model into game creation, asking it for a Minecraft-like voxel world, a battle royale prototype, and a GTA-style open world. The most interesting detail was not that every output was production-ready. It was that the demos were playable enough to feel like real prototypes rather than static screenshots.
DesignCourse took a different angle: one-shot UI and UX work. The tests included portfolio-style pages, 3D gallery concepts, hero section improvements, a Craigslist modernization, and animated interface recreation. The takeaway for designers was direct: people with taste and intent can use stronger models to move from idea to browser faster.
Pat Simmons ran a cleaner head-to-head: the same prompts into Opus 4.8 and Fable 5, including an e-commerce app, a 3D art museum, and an Age of Empires-style RTS. The value of that format is that it reduces prompt cherry-picking. In his test, Fable 5 produced cleaner, more navigable, more coherent builds on the demanding prompts.
Benchmarks, With The Right Caveat
Benchmarks are useful, but they need labels. Anthropic's launch post includes an official benchmark table for Claude Mythos 5 and Fable 5, including reported scores such as 80.3% on SWE-Bench Pro, 85.0% on OSWorld-Verified, and 88.0% on Terminal-Bench 2.1. WorldofAI described Fable 5 as strong across software engineering, browser use, vision, science research, long-context workflows, and agentic tasks.
The practical rule is simple: treat official tables as vendor claims, creator videos as useful demonstrations, and your own work samples as the adoption test. Do not buy a model purely from leaderboard screenshots. Buy a workflow result.
- Treat official Anthropic claims, creator demos, and your own benchmarks as three different evidence layers.
- Run Fable 5 on tasks your current model finds hard, not on prompts designed for a highlight reel.
- Measure review time, output acceptance, refusal behaviour, and final cost per finished task.
Where Sonnet 5 Fits Now
The same Universe of AI briefing also discussed Sonnet 5, and Anthropic's newsroom lists Sonnet 5 as a June 30 product launch for coding, agents, and professional work at scale. Sonnet 5 may be a stronger everyday model for knowledge work, planning, and mid-tier automation. Fable 5 is the larger return story because it is the model builders wanted for the hard jobs.
This is how a serious AI stack should work. Sonnet 5 can carry routine drafting, summarisation, support workflows, and ordinary planning. Fable 5 should be routed to problems where extra reasoning pays for itself: deep code changes, multi-document synthesis, high-stakes analysis, and long-running agent tasks.
The Hard Lesson From The Shutdown
Greg Isenberg focused on the uncomfortable part of the story: cloud frontier models are rented access. They can change because of policy, safety review, pricing, terms, region, or provider decisions. The answer is not to stop using frontier models. The answer is to avoid building brittle systems around a single endpoint.
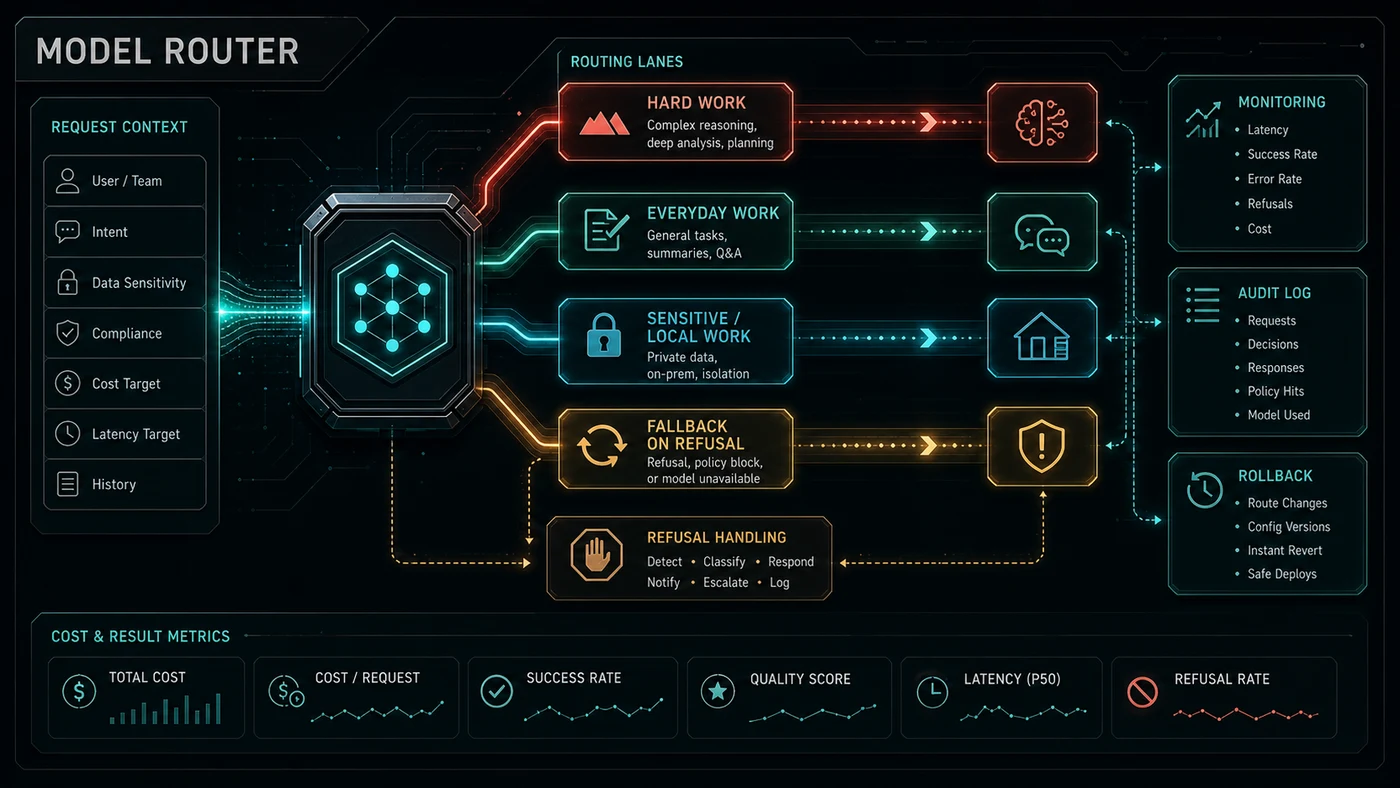
For businesses, this means having a frontier model layer, a cheaper everyday model layer, and a local or alternate-provider fallback for sensitive or continuity-critical work. Fable 5 can be the best tool for certain jobs and still not be your only tool.
It also means your policy needs a refusal path. Anthropic says Fable 5 can decline some requests through safety classifiers and that API refusals return as successful HTTP 200 responses with stop_reason: "refusal", not as ordinary errors. That is fine if your workflow expects it. It is a production bug if your workflow treats every 200 response as success.
Implementation Pattern For Australian Teams
For Australian founders, agencies, professional services firms, and technical teams, the right next step is a controlled evaluation, not a blanket migration. Fable 5 should earn a production lane by outperforming the existing route on a known workload.
- Owner: assign one technical owner for model evaluation, one business owner for workflow fit, and one reviewer for data exposure.
- Inputs: use real code, documents, transcripts, SOPs, support cases, and design prompts with permission to test them.
- Outputs: require usable diffs, decision briefs, prototypes, research summaries, and action plans, not generic chat answers.
- Review checkpoint: keep human review before customer delivery, deployment, legal or compliance use, security advice, or staff-facing policy changes.
- Success metric: measure accepted output rate, review time saved, fallback rate, cost per accepted result, and number of human rewrites needed.
- Rollback: keep Sonnet 5, Opus-class models, or local/open-weight options ready for tasks that Fable 5 refuses, over-costs, or should not process externally.
A Seven-Day Return Playbook
The best response to Fable 5 coming back is a focused seven-day evaluation. Do not spend the first week arguing online. Use the window to test real workflows and decide where the model deserves a production lane.
- Day 1: collect 10 to 20 real tasks where your current model struggles.
- Day 2: run Fable 5, Sonnet 5, your current production model, and at least one fallback model on the same tasks.
- Day 3: score outputs for correctness, depth, usability, implementation quality, and required human cleanup.
- Day 4: test long-context work with full documents, transcripts, repos, SOPs, and customer histories.
- Day 5: test tool workflows, including code changes, retrieval, browser tasks, spreadsheets, and multi-step agent plans.
- Day 6: write the routing policy: what goes to Fable 5, what stays on cheaper models, and what cannot be sent externally.
- Day 7: move only the winning workflows into production monitoring.
What To Build Next
The return of Fable 5 should push teams toward better systems, not noisier demos. The obvious next builds are a code-review harness, a long-document research assistant, a design-to-browser prototyping lane, and an internal automation planner that can turn messy SOPs into task graphs with a human approval point.
The deeper opportunity is to combine frontier model quality with disciplined operating design. Put Fable 5 behind a router. Record what it was asked to do. Keep source material and prompts under version control. Use synthetic or redacted data when the workflow touches sensitive Australian customer or staff information. Then keep the parts that pass the review.
Source Trail
Primary references for this briefing include Anthropic's launch post (opens in a new tab), June 12 suspension statement (opens in a new tab), June 30 redeployment post (opens in a new tab), and Claude Platform docs (opens in a new tab). Independent context came from WIRED (opens in a new tab), The Verge (opens in a new tab), and Axios (opens in a new tab). The export-control decision was a US government action. Creator tests are linked above and treated as attributed demonstrations, not official proof.
The generated visuals in this article are AI Kick Start editorial explainers. They are not official Anthropic screenshots, not benchmark evidence, and not a substitute for checking the original sources before making a buying, compliance, or production decision.
Bottom Line
Fable 5 returning is good news. The access restriction lift gives builders a chance to revisit the model while the memory of the shutdown is still fresh. That combination is useful: excitement with discipline.
If Fable 5 performs in your workloads the way it appeared to perform in the strongest launch and creator tests, it belongs in the high-value layer of the AI stack: complex coding, long documents, serious research, visual prototyping, agent planning, and business automation where quality compounds. Celebrate the return, rerun the tests, and build the workflow so one model going away never stops the business again.


