

The Short Version
Claude Sonnet 5 is not a model to dismiss, but it is also not a model I would roll into production just because the launch numbers look strong. Anthropic's own documentation positions it as a Sonnet-family upgrade with 1M context, adaptive thinking, stronger coding and agentic capability, and introductory API pricing through August 31, 2026. The WorldofAI test video adds the useful counterweight: when you run real coding, UI, game, and SVG tasks, the cost per finished result can still be awkward.
For AI Kick Start clients, the decision is simple: do not judge Sonnet 5 on benchmark claims or a single demo. Judge it on your own workflow regression set. If it finishes the same job faster, cheaper, and with less review effort, it earns a place. If it burns more tokens, needs more retries, or produces weaker visual/code output, keep it as a specialist option instead of a daily default.
My working position: pilot it, measure it, and keep a fallback. That is especially true for coding agents, long-context document work, customer-facing automations, and anything where the model is allowed to use tools.
What the Source Video Actually Tested
The WorldofAI video is useful because it does more than read a launch page. It checks the model against practical creative and coding tasks, then compares the experience against expectations for a Sonnet-class model. The headline is harsh, but the underlying question is fair: does Sonnet 5 deliver enough output quality for the tokens and time it consumes?
- A pricing and benchmark review, including the difference between headline token rates and real workflow cost.
- A macOS-style desktop clone with working app windows, tool-like interactions, and a first-person game test.
- A Minecraft-style block game prototype with water, mobs, placement, breaking, and rough terrain behaviour.
- A SaaS landing page generation task to see whether the model can produce usable product marketing UI.
- An SVG car illustration test, where visual identity, geometry, and creative precision matter.
That mix is exactly why the video is worth turning into a business article. Most teams do not need another abstract model ranking. They need to know whether a new model will improve their real tickets, real automations, real design work, and real operating cost.
Official Launch Claims vs Hands-On Reality
Anthropic's docs describe Claude Sonnet 5 as the next Sonnet generation, a drop-in upgrade from Sonnet 4.6, and the best combination of speed and intelligence in the current Sonnet tier. That is the official positioning. The hands-on review asks a different question: does that positioning survive messy jobs?
| Area | Official signal | Practical interpretation |
|---|---|---|
| Model ID | claude-sonnet-5 | Update configs deliberately and keep the old model available while you compare results. |
| Context | 1M token context window | Useful for large documents and repos, but still needs chunking, retrieval discipline, and cost limits. |
| Pricing | $2/$10 per million input/output tokens through August 31, 2026, then $3/$15 | The launch discount helps, but the final bill depends on tokenisation, retries, tool calls, and review time. |
| Tokenizer | Anthropic says the same input can produce about 30% more tokens than Sonnet 4.6 | Recount your real prompts before assuming the migration is cheaper. |
| Agentic coding | Anthropic points to the largest gains in coding and agentic tasks | Benchmarks are a signal, not a substitute for your repo, your tests, and your acceptance criteria. |
This is the main lesson: the official story and the review video can both be true. Sonnet 5 can be a capable model and still be a poor default for a specific team if the workflow economics do not hold.
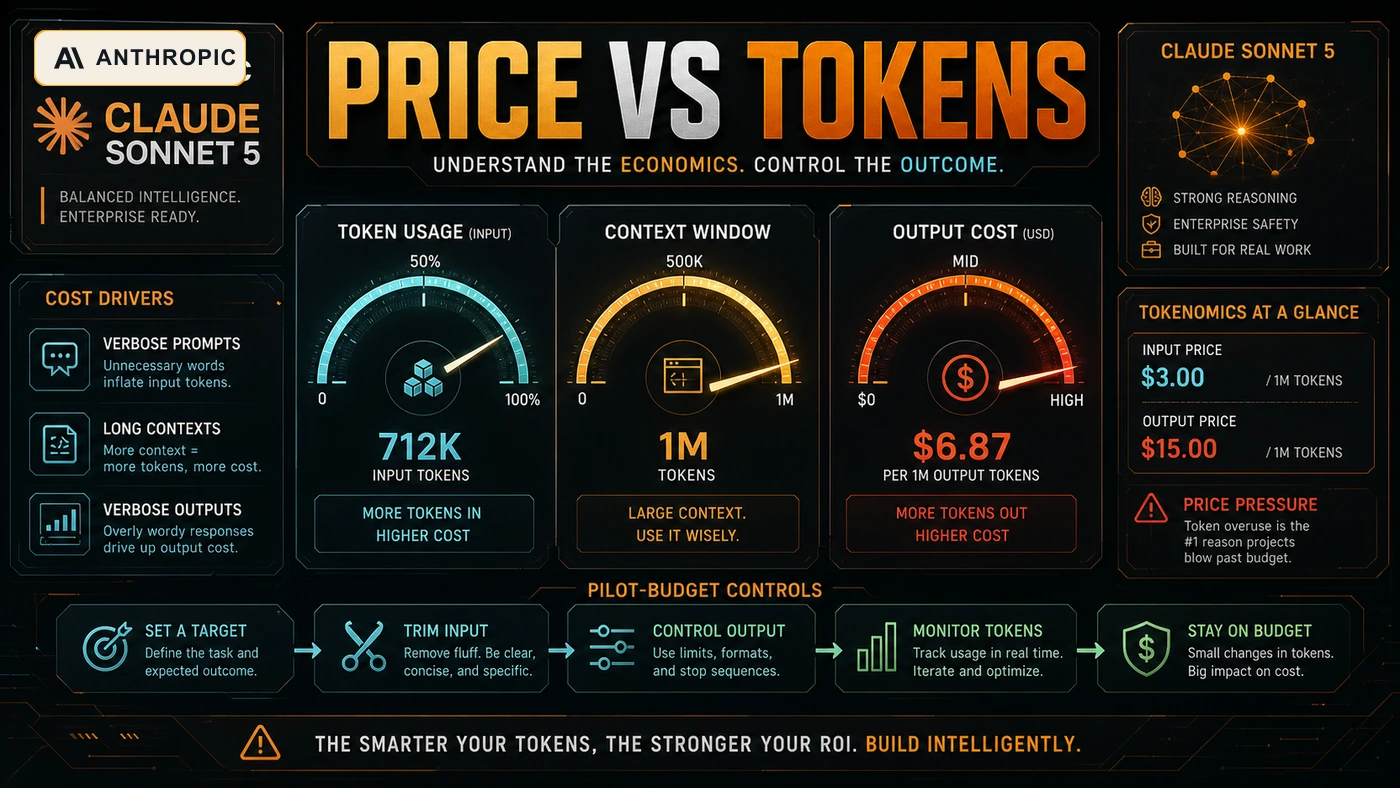
The Pricing Trap: Cheap Per Token Is Not Cheap Per Outcome
The introductory price is the part most people will notice first. On paper, Sonnet 5 looks attractive because the launch pricing is lower than the standard Sonnet rate until August 31, 2026. That is useful, but it is not the whole story.
Anthropic's own migration notes matter here: Sonnet 5 uses a new tokenizer, and equivalent input can produce roughly 30% more tokens than Sonnet 4.6. That does not make the model bad. It means your old token budget is no longer a reliable estimate. For long prompts, codebases, logs, PDFs, and agent traces, that difference can move the cost line quickly.
The video makes the same point from the other side. A model can look cheaper per million tokens and still cost more per completed task if it takes more reasoning steps, produces more intermediate output, or needs more human correction. In business terms, the unit to measure is not tokens. The unit is a finished job.
- Measure cost per accepted pull request, not cost per prompt.
- Measure cost per reviewed customer response, not cost per chat.
- Measure cost per usable design output, not cost per image or SVG attempt.
- Measure cost per automated workflow completed with a human checkpoint, not cost per tool call.
Coding Test Results: Good Output, Expensive Path
The strongest part of the video was the coding and app-generation work. Sonnet 5 produced a credible macOS-style interface with multiple working surfaces and a playable first-person game test. That is not trivial. It shows enough planning and code generation ability to take seriously.
The weaker part is the path to get there. The reviewer called out long run time and heavy token use. For a hobby test, that is interesting. For a business using AI coding agents every week, that is a budget and governance question. If a model can build impressive prototypes but needs more time, more tokens, and more review, the team needs to know before it becomes the default.
The block-game test is a good example. Dynamic water, mobs, blocks, and environment behaviour are useful signs. Missing inventory depth, rough cave generation, and glitchy movement are also useful signs. They tell you where the model can generate a first pass and where a developer still needs to own the system design.
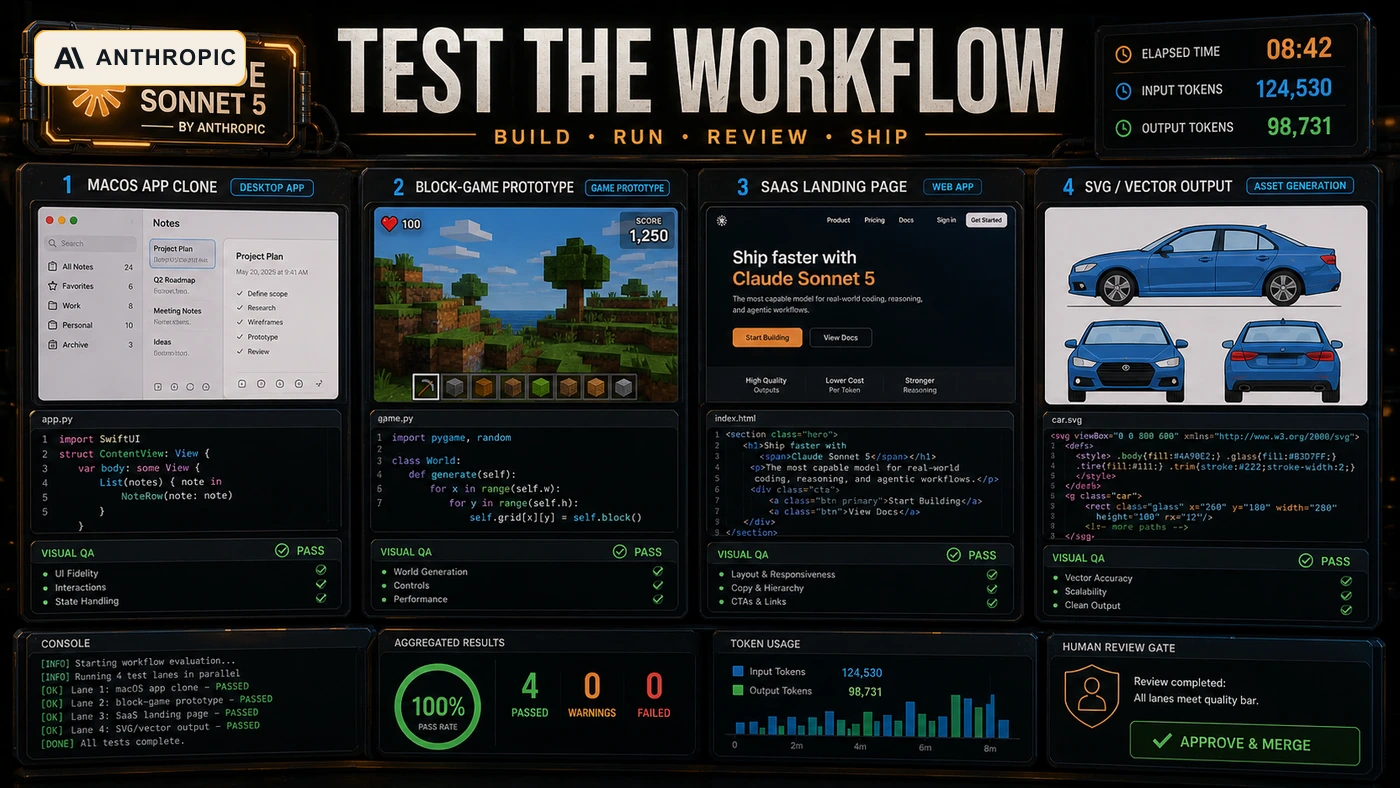
The UI and SVG Tests Are the Warning Sign
The SaaS landing page and SVG car test are where I would be careful. Front-end and visual tasks are not just code tasks. They involve brand judgement, layout discipline, hierarchy, responsiveness, and small details that users immediately feel. The video's results were serviceable in places, but not enough to remove human design review.
For AI Kick Start work, this is exactly why we keep design acceptance criteria separate from code completion. A model can produce a React component that compiles and still miss the brand, visual balance, or mobile layout. A model can produce an SVG and still fail the actual object identity. Passing build is not the same as passing product.
If your team uses Claude for front-end work, keep a visual QA loop: desktop, mobile, keyboard navigation, text overflow, asset loading, and brand fit. Sonnet 5 may help produce the first version faster, but the final call still belongs to someone with product judgement.
Where Sonnet 5 May Still Make Sense
The cautious read is not the same as a rejection. There are plenty of places where Sonnet 5 may be the right model, especially during the introductory pricing window. The point is to assign it to the right jobs.
- Everyday Claude chat where speed, broad usefulness, and lower cost matter more than maximum reasoning depth.
- First-pass code exploration where a developer will review the result before merge.
- Large-context document triage where the 1M context window is genuinely useful and the output is reviewed.
- Internal agent workflows with tight permissions, capped budgets, and clear acceptance tests.
- Research and planning tasks where a slightly weaker creative result is acceptable if the model is cheaper and fast enough.
It is also worth watching the model over the next few weeks. Prompting patterns, provider routing, IDE integrations, and agent harnesses often improve after a launch. The smart move is to keep a clean test set so you can re-run the comparison later instead of relying on launch-day impressions.
Where I Would Not Rush It Into Production
I would not rush Sonnet 5 into high-impact workflows without a proper comparison. The risk is not that the model is unusable. The risk is that a team swaps defaults, sees a few impressive demos, and only discovers the cost, quality, or migration issues after the workflow is already embedded.
- Customer-facing support automation without human review and refusal handling.
- Finance, HR, legal, medical, or compliance workflows where a small error has a real consequence.
- Long-running autonomous agents that can spend tokens and call tools without strict limits.
- Brand-critical front-end, creative, SVG, or marketing design work without visual QA.
- Cost-sensitive batch jobs where the new tokenizer has not been measured against your real input.
There is also a migration detail teams should not skip: Sonnet 5 changes behaviour around adaptive thinking, manual extended thinking, and sampling parameters. If your API wrapper still sets old thinking budgets or non-default sampling parameters, you may need code changes before the model is a clean swap.
AI Kick Start Rollout Plan
Here is the rollout path I would use for a business or technical team evaluating Claude Sonnet 5.
- Pick five real tasks: one code change, one long document review, one customer response, one planning task, and one visual or front-end task.
- Run each task through your current default model and Sonnet 5 with the same input, same tooling, and same acceptance criteria.
- Record total tokens, wall-clock time, retries, human edits, test failures, and final acceptance.
- Check API compatibility: model ID, adaptive thinking, removed manual extended thinking, sampling parameters, max token limits, and refusal handling.
- Set budget limits before any agent run. Do not let a new model explore tool use without a cap.
- Ship only the narrow workflow where Sonnet 5 wins. Keep Opus, Sonnet 4.6, or your current model available as the fallback.
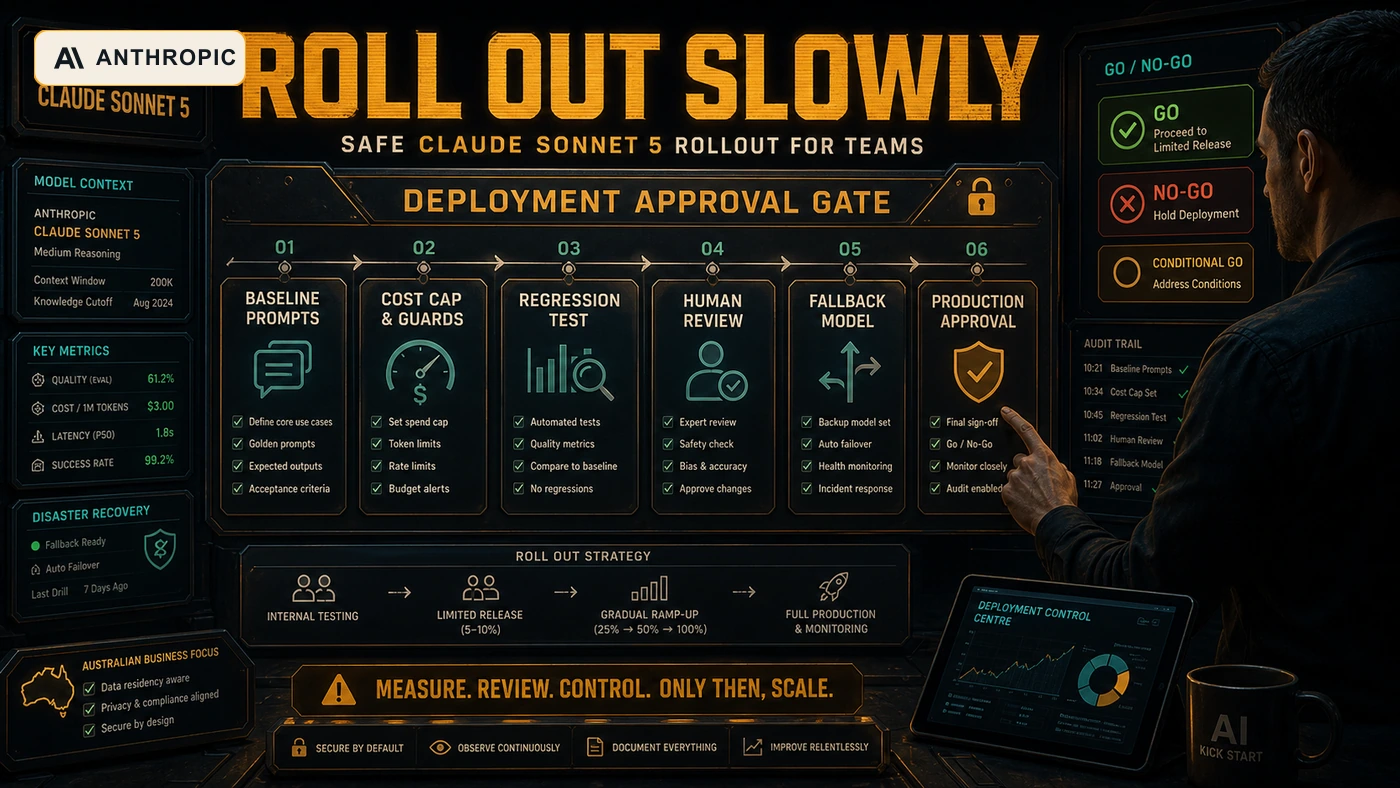
The winning model is the one that improves the workflow after all costs are counted. That includes the token bill, the developer review time, the operator's confidence, the error rate, and the rollback story.
Final Take
Claude Sonnet 5 looks like a serious model, but it should be treated as a measured upgrade, not a magic default. Anthropic's docs give it a strong platform story: 1M context, adaptive thinking, agentic improvements, current platform availability, and an introductory price window. The WorldofAI test video gives the practical warning: impressive output still needs to be judged against token use, time, visual quality, and finished-workflow economics.
For most teams, the correct move is not to ignore Sonnet 5 and not to jump blindly. Build a small test harness, use real work, track the actual cost per accepted result, and let the evidence decide.


