










Analysis
Picture an AI agent running in your business overnight. It edits code, calls tools, spends money on model tokens, and makes dozens of small decisions without anyone watching. In the morning, something is broken. The obvious question is the one most teams cannot answer: what did the agent actually do, and why?
That gap is the whole story here. When a human employee makes a bad call, you can ask them about it. When an autonomous agent makes one, you are left with whatever it bothered to record. If it recorded nothing, you are guessing.
The teams getting real value from agents in 2026 have figured this out. They treat monitoring as part of shipping the agent, not as an afterthought you bolt on once something goes wrong. The good news is that the tooling has caught up. The standard observability stack most engineering teams already run can watch agents too, once you know which signals matter.
So this is the practical version: what to log, what to trace, what to measure, and how to wire it into tools you probably already have.
Why Agent Monitoring is Different
Ordinary application monitoring watches three things: errors, performance, and availability. Agents need all of that, plus a few dimensions that traditional monitoring never had to care about (Claude Code Docs, 2026):
- Intent tracking: What did the agent think it was doing?
- Decision tracing: Why did it pick that approach over another?
- Tool call telemetry: Every tool invocation, with its parameters and results.
- Context window analysis: What was actually in context when each decision was made?
- Quality metrics: Was the output correct, safe, and aligned with the goal?
- Cost tracking: Token usage, model selection, and spend per task.
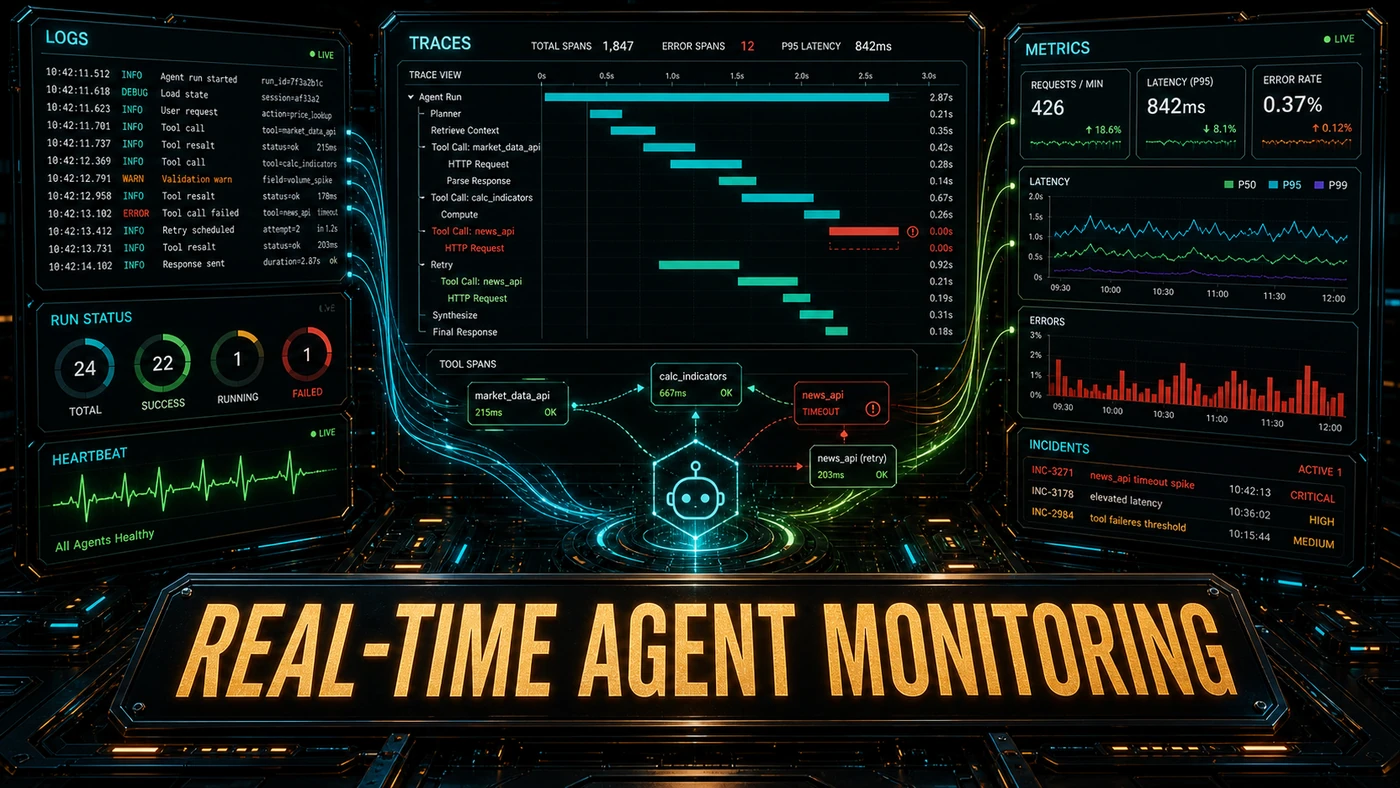
The Three Pillars of Agent Observability
Pillar 1: Logging
Structured logging records every agent action along with its context:
{
"timestamp": "2026-06-15T10:30:00Z",
"agent_id": "hermes-prod-1",
"session_id": "sess_abc123",
"event_type": "tool_call",
"tool": "file_write",
"params": {
"path": "src/auth.ts",
"lines": 47,
"diff_hash": "sha256:abc..."
},
"model": "sonnet-4.8",
"tokens_used": { "input": 4200, "output": 1800 },
"latency_ms": 3200,
"result": "success",
"user_id": "engineer_42"
}(The sonnet-4.8 model id above is illustrative. As of June 2026 the released Sonnet line tops out at Sonnet 4.6; there is no public Sonnet 4.8. Anthropic did ship Claude Opus 4.8 in late May 2026, but treat the field here as a placeholder rather than a real version.)
Different agents log in different ways. Hermes (Nous Research) is built on a SQLite state store that uses an FTS5 full-text-search table, so the data it keeps lives in a searchable local database (NousResearch/hermes-agent); whether you can lean on that as a full monitoring layer depends on how you wire it up. Claude Code emits structured log events through its built-in OpenTelemetry instrumentation, covering prompts, tool results, token usage, and costs, and you turn it on with CLAUDE_CODE_ENABLE_TELEMETRY=1 (Claude Code Docs, 2026). The tool sometimes referred to as OpenClaw reportedly logs to files with configurable verbosity, though that project and its commands could not be confirmed against a primary source, so take it as unverified.
Pillar 2: Tracing
Distributed traces follow a single task across multiple agent calls and tool invocations:
[Trace: migrate-auth-system]
[Span: plan_generation] 1.2s
[Span: codebase_analysis] 0.4s
[Span: migration_plan_draft] 0.8s
[Span: plan_approval] 45.0s (human)
[Span: execution] 128.0s
[Span: file_read(src/auth.ts)] 0.1s
[Span: file_write(src/auth.ts)] 3.2s
[Span: test_run] 12.4s
[Span: file_write(tests/auth.test.ts)] 2.8s
[Span: verification] 8.1s
[Span: lint_check] 2.1s
[Span: typecheck] 6.0sA trace shows you where the time went and where the failure happened. In Claude Code, this comes from the OpenTelemetry instrumentation, which records spans around each model request and tool execution (Claude Code Docs, 2026). Its Dynamic Workflows feature is real (a script that orchestrates subagents at scale), but the idea that it generates traces on its own overstates things: tracing is the job of the opt-in OpenTelemetry layer, not a side effect of running a workflow. For Hermes, an OpenTelemetry integration via a hermes-opentelemetry package has been mentioned, but no registry or repo confirms such a package exists, so treat it as unconfirmed.
Pillar 3: Metrics
Aggregate metrics are what feed your dashboards and alerts:
| Metric | Type | Alert Threshold |
|---|---|---|
| Tasks per hour | Counter | Drop >50% |
| Success rate | Gauge | <80% |
| Average latency | Histogram | p95 >60s |
| Token cost per task | Histogram | >200% of baseline |
| Rollback rate | Gauge | >5% |
| Approval gate triggers | Counter | Spike >300% |
| Tool error rate | Gauge | >2% per tool |
Monitoring Stack Recommendations
For Small Teams (< 10 engineers)
Hermes: Built-in FTS5 logs + `hermes metrics` command
Claude Code: Built-in telemetry + JSON log export
OpenClaw: File logs + basic metrics dashboard
Export to: Grafana Cloud (free tier) or DatadogA note on those Hermes and OpenClaw commands: the specific subcommands shown here are illustrative. Hermes ships a CLI, but the trace, metrics, and dashboard verbs below were not confirmed in its primary docs, and the OpenClaw commands could not be verified at all. Claude Code's telemetry, by contrast, is documented, and its OpenTelemetry export feeds Grafana, Datadog, and similar backends directly (Claude Code Docs, 2026).
For Large Teams (10+ engineers)
Hermes: OpenTelemetry export to Jaeger + Prometheus
Claude Code: Anthropic-managed telemetry + SIEM integration
OpenClaw: Structured logging to ELK/Loki stack
Dashboards: Grafana with custom agent dashboards
Alerting: PagerDuty/Opsgenie for critical thresholdsThe SIEM piece is worth flagging because it is real and useful: Claude Code's tool_decision, tool_result, mcp_server_connection, and permission_mode_changed events form a per-user audit trail you can forward to a security information and event management platform (Claude Code Docs, 2026). Grafana, Jaeger, Prometheus, ELK, Loki, PagerDuty, and Opsgenie are all standard tools, and OpenTelemetry's OTLP export plugs into them, so this stack is technically sound rather than aspirational.
Real-Time Dashboards
A useful agent dashboard surfaces:
- Current activity: Active agents, running tasks, queued requests.
- Health overview: Success rates, error rates, latency percentiles.
- Cost tracking: Spend today, this week, this month, broken down per agent.
- Quality trends: Rollback rate, human correction rate, approval gate stats.
- Alert feed: Active alerts and recent resolutions.
# Hermes built-in dashboard
hermes dashboard --port 8080
# Claude Code telemetry export
claude telemetry export --format prometheus
# OpenClaw metrics
openclaw metrics --serve --port 9090One caveat on the Claude Code line: there is no documented claude telemetry export --format prometheus subcommand. In practice you configure the export through OpenTelemetry environment variables (OTEL_METRICS_EXPORTER and the standard OTLP settings), and a Prometheus or Grafana backend consumes the metrics from there (Claude Code Docs, 2026). Read the command above as shorthand for "point your OTEL config at Prometheus."
Alerting Best Practices
- Alert on symptoms, not causes: "Success rate dropped," not "CPU usage high."
- Use dynamic thresholds: Static thresholds breed alert fatigue. Lean on anomaly detection.
- Include context: An alert should link straight to the relevant traces and logs.
- Escalation paths: Low-priority alerts to Slack, high-priority to PagerDuty.
- Review regularly: A weekly alert review to clear out false positives.
Debugging with Traces
When an agent does something you did not expect, the trace is the first place to look:
# Find the failing trace
hermes traces list --since 1h --status failed
# Inspect the trace
hermes traces show trace_abc123 --format tree
# Compare with a successful trace
hermes traces compare trace_abc123 trace_def456The comparison shows where two runs diverged: a different tool choice, different context, a different model response. That is usually enough to pin down the root cause. (As above, the exact hermes traces verbs are illustrative and not confirmed in the project's primary docs, but the workflow holds for any tracing tool you adopt.)
Monitoring is not optional for production agents. An agent you cannot see is a risk on your books. An agent you can see, with logs, traces, and metrics behind it, is an accountable member of the team.