

Introduction: Why This One Belongs on the Watchlist
This video is not a product demo or software release. It is a hardware-leak round-up from a gaming channel. The reason it matters for AI Kick Start readers is practical: this is not just another launch to admire from a distance. It changes how founders, operators, and technical teams should think about AI Infrastructure work over the next few months. The source transcript repeatedly centres on Olympic Ridge, Mustang Peak and Serpent Lake, with the video framing the topic as a practical workflow rather than a detached product announcement. That is the useful lens. The video is worth treating as implementation intelligence: what should be tested, what should be ignored for now, and what should become part of a repeatable operating system. For Australian small businesses and technical teams, the right question is not "is this impressive?" The right question is "where does this reduce friction without creating a larger governance, security, or maintenance problem?"
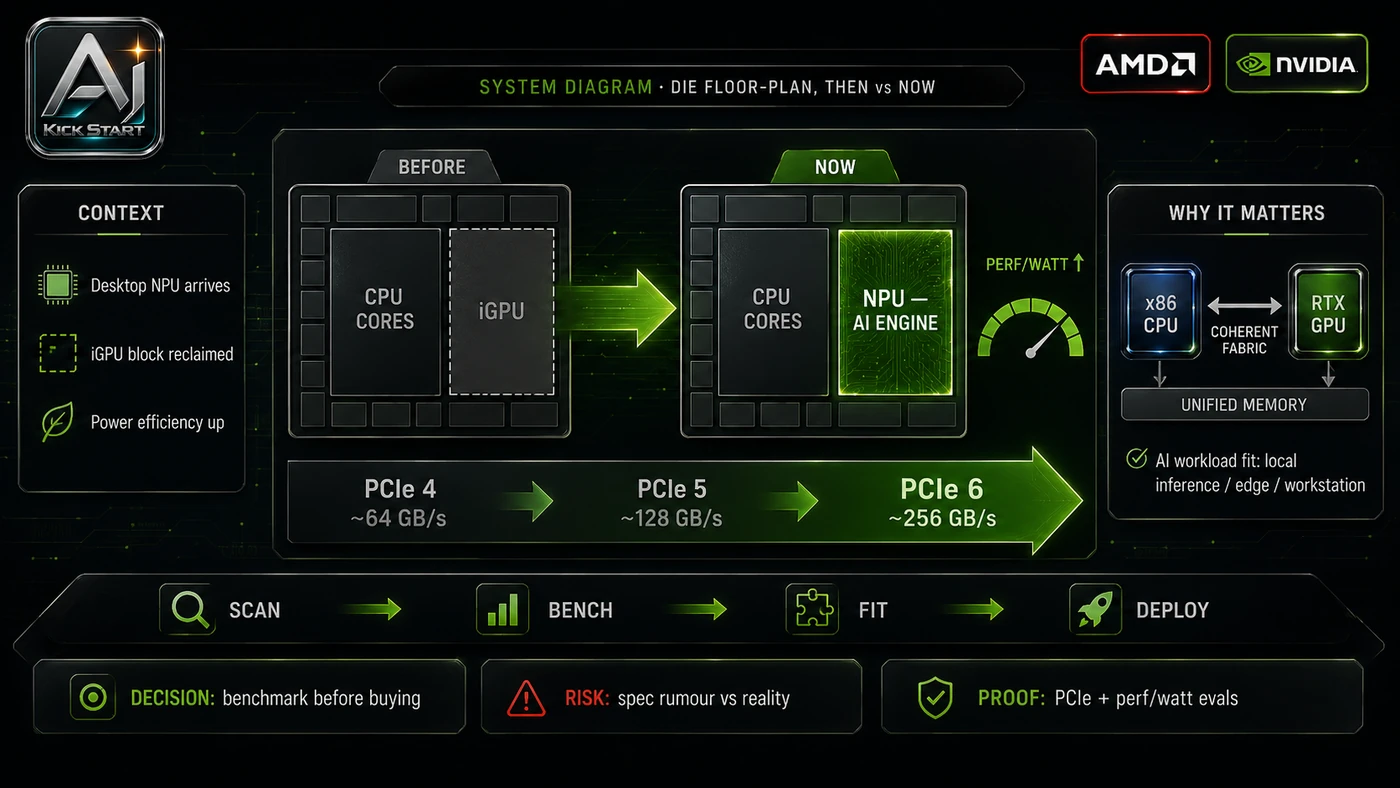
What the Video Actually Shows
The core pattern is simple: the major x86 vendors are betting that local AI acceleration belongs on the CPU package. AMD is rumoured to replace the integrated GPU in mainstream desktop Ryzen chips with an integrated NPU in "Olympic Ridge"; AMD has accidentally confirmed its next-generation Threadripper workstation platform, codenamed Mustang Peak, with Zen 6 cores, DDR5, and PCIe Gen 6; and Intel and Nvidia are reportedly teaming up to ship x86 SoCs with integrated RTX graphics chiplets, possibly as early as the first quarter of 2028. In practice, that means the update sits inside a broader shift from isolated AI prompts to managed systems. A tool, model, or method only becomes valuable when it has clear inputs, a measurable output, a review path, and a way to repeat the result next week. The video's most useful signal is the workflow shape. The moving parts can be summarised as: Workload profile Hardware test harness Review gates Platform churn plan That is the level at which teams should evaluate it. A demo can be entertaining, but a workflow must survive messy source files, staff handoff, data boundaries, and real deadlines.

The Implementation Pattern
The first implementation lesson is to narrow the scope. If your team is planning local AI inference, edge deployments, or on-premise RAG, start with one representative model and pipeline rather than refreshing the whole fleet. Broad adoption is usually where AI systems fail first because nobody knows which decision the tool is allowed to make and which decision still belongs to a human. The second lesson is to create a test harness. Run one or two candidate machines through your actual inference, embedding, and data-pipeline workloads. A useful harness does not have to be complicated. It can be a short brief, a fixed sample dataset, a few expected outputs, and one person responsible for judging whether the result is good enough. The third lesson is to capture the process. Document why you chose GPU over NPU, or discrete over integrated, before the next generation arrives. When the process is documented, it can become a reusable skill, checklist, prompt pack, repo pattern, or operating procedure. When it is not documented, the team is back to improvising in chat.
Research Update: What To Correct
This update adds a current-source pass rather than treating the original video summary as enough. The important corrections are the product surface, plan or pricing constraints, and what should be verified before a team depends on the workflow. The Mustang Peak Threadripper appeared on AMD's technical information portal as Family 1Ah Model A8h, based on Zen 6, on a 2 nm-class TSMC node, with DDR5 and PCIe Gen 6 support, and a new TR6 socket. The "Olympic Ridge" desktop Ryzen replacing the integrated GPU with an NPU comes from a single X leaker and remains speculation, even though Intel already puts NPUs in desktop Core Ultra chips. Intel and Nvidia officially announced in 2025 that they would jointly develop x86 SoCs with integrated Nvidia RTX GPU chiplets for PCs, but the "Serpent Lake" codename and Q1 2028 launch window are leaks. The correction that matters: do not budget around these products today; budget around the evaluation process.
Practical Setup and How-To
The useful next step is a controlled pilot with a named owner, fixed inputs, a measurable output, and a review point. Use the sequence below as the first implementation path before expanding the workflow. Audit your current local AI footprint and list every machine that runs inference, embedding, transcription, OCR, or small-language-model workloads on-premise or at the edge. Profile one representative workload, measuring tokens-per-second, batch throughput, and wall-clock latency. Create a candidate-hardware scorecard covering framework support, memory bandwidth, accelerator TOPS, cooling and power, socket longevity, and driver maturity. Set a re-evaluation calendar with a 30-minute hardware review after each major launch window, and document the decision criteria before the next generation arrives.
Pricing, Access, and Comparison Notes
Pricing and access should be checked at implementation time because AI products change quickly. The safer decision is to compare the tool against the job-to-be-done, not against launch hype. There are no official prices yet, but the comparison dimensions are already clear. Ryzen desktop with NPU fits edge kiosks, front-desk terminals, and very small local models where low-power inference and Copilot+ certification matter more than peak TOPS. Threadripper Pro "Mustang Peak" fits on-premise data-prep, retrieval index serving, and multi-GPU inference hosts that need core count and PCIe Gen 6 bandwidth. Intel + Nvidia x86 SoC fits compact AI workstations, mobile AI development, and CUDA-dependent edge apps, assuming the memory architecture and driver integration hold up. Access Plan, preview status, region, account type, admin controls, and rate limits. Cost Subscription, credits, API tokens, retries, hardware, review time, and support burden. Fit Workflow reliability, data handling, output quality, observability, and human approval needs.
Implementation Notes for Teams
For AI Kick Start readers, this is the production filter: keep the first rollout narrow, make the evidence visible, and do not let the tool cross a business boundary until the review model is clear. Do not let "AI PC" or "Copilot+" marketing drive procurement, because certification programmes are not performance guarantees. Watch the software stack, not just the silicon: an NPU that your inference engine cannot see is dead silicon, so verify ONNX Runtime, OpenVINO, DirectML, or ROCm support before you buy. Treat socket changes as a platform reset and factor TR6 motherboards, coolers, and memory into total cost of ownership. Keep a cloud fallback for spikes, retraining, and models that outgrow the local box, and document driver and firmware versions in your runbook.
Screenshot and Visual Guidance
The second inline image for this article should make the implementation concrete: a one-page workload profile with model size, batch size, token target, and current latency; a comparison matrix of candidate platforms, updated quarterly; a decision log that records why the current hardware choice was made; and vendor documentation links and launch dates labelled "confirmed / leaked / speculation." If the team is documenting a real rollout, capture setup screens, before/after outputs, permission settings, cost meters, and review evidence rather than decorative screenshots.
Where It Fits for Real Teams
For founders, the opportunity is speed with evidence. For operators, the value is consistency. For technical teams, the value is leverage. These signals matter most for edge and field teams where power, size, or fan noise matter; on-premise data and ML teams that need fast storage and accelerator bandwidth; and founders watching capital efficiency who want a one-package CPU+GPU design with a stable software stack. The practical fit is strongest when the task has clear source material, a known output format, and a low-cost way to verify quality. It is weaker when the task is vague, politically sensitive, legally risky, or dependent on facts that cannot be checked.
Trade-offs and Risks
The main risk is premature standardisation. That risk can be managed, but only if it is named before the workflow becomes normal. A second risk is marketing over fit. AI systems often look better in a screen recording than they feel inside a production workflow. The test is whether the result is repeatable when the source material changes, the operator changes, and the deadline is real. A third risk is platform churn and neglecting the integration layer. This is why AI Kick Start generally recommends a staged rollout: sandbox first, internal use second, customer-facing deployment last.
The Next Sensible Test
The next sensible test is a small controlled implementation. Pick one workflow, one owner, one expected output, and one acceptance check. Run it twice. If the second run is easier than the first, the pattern is worth keeping. Do not judge the workflow by the best possible demo. Judge it by the worst acceptable production case. Ask: what happens when the source file is incomplete, the tool is unavailable, the output is wrong, or a staff member needs to explain the result to a customer? If those answers are clear, this belongs in the roadmap. If they are not, it belongs in the lab until the operating model catches up.


