






Analysis
For two decades, the deal behind every leap in AI was simple: feed the machine more of the internet. Bigger models, more text, better answers. That deal is quietly falling apart, because the labs are running out of internet to feed it.
So they have started making their own. A growing share of what trains today's frontier models isn't scraped from human writing at all. It's text, code, and images produced by other AI models, on purpose, to teach the next one. The polite term is synthetic data. Less politely: the machines are now teaching the machines.
For a business reader, the "so what" is worth sitting with. If the next generation of AI is increasingly trained on AI output, two things follow. It sidesteps a lot of the copyright and privacy fights that have dogged the industry, which is good news for regulated sectors like health and finance. And it introduces a new failure mode, where models trained too heavily on their own kind slowly go stale, a problem researchers have a name for: model collapse.
What follows is how the labs are actually doing this, where it works, and where it bites.
The AI industry's hunger for training data doesn't let up. GPT-4 was trained on an estimated 13 trillion tokens, and more recent models have run well past that. (Specific token counts for newer releases like Llama 4 and GLM-5.2 get quoted loosely and often inaccurately, so treat any single headline figure with caution.) Either way, these numbers cover a large slice of the high-quality text on the public internet, and they're closing in on the limit of what's actually out there.
That scarcity has changed how models get built. Synthetic data has gone from a side experiment to a standard part of the training pipeline at every major lab. The shift isn't small. Gartner estimated that around 60% of the data used in AI projects was synthetic by 2024, up from a tiny fraction a few years earlier, and reporting puts the synthetic share of recent frontier-model training data somewhere in the 30-60% range.
The Techniques
A few synthetic data methods have held up at scale.
"Self-improvement," or iterative bootstrapping, has one model generate training examples, filters them for quality using the same model or a second one, then trains an improved version on what survives. It works especially well for coding, where a model can churn out thousands of programming problems and solutions, check each for correctness, and keep only the ones that pass.
"Agentic generation" puts several AI agents into a structured workflow to build harder training data. One agent writes a prompt, another answers it, a third grades the answer for quality and correctness, and a fourth reformats the result for training. Splitting the job up tends to produce cleaner data than a single model working alone, and it can cover tasks too complex for any one model to handle end to end.
"Curriculum generation" builds data in a deliberate easy-to-hard progression. The model starts with simple examples, trains on them, then generates slightly harder ones based on what it just learned. It echoes how people are taught, and it's been useful for maths reasoning and logic tasks.
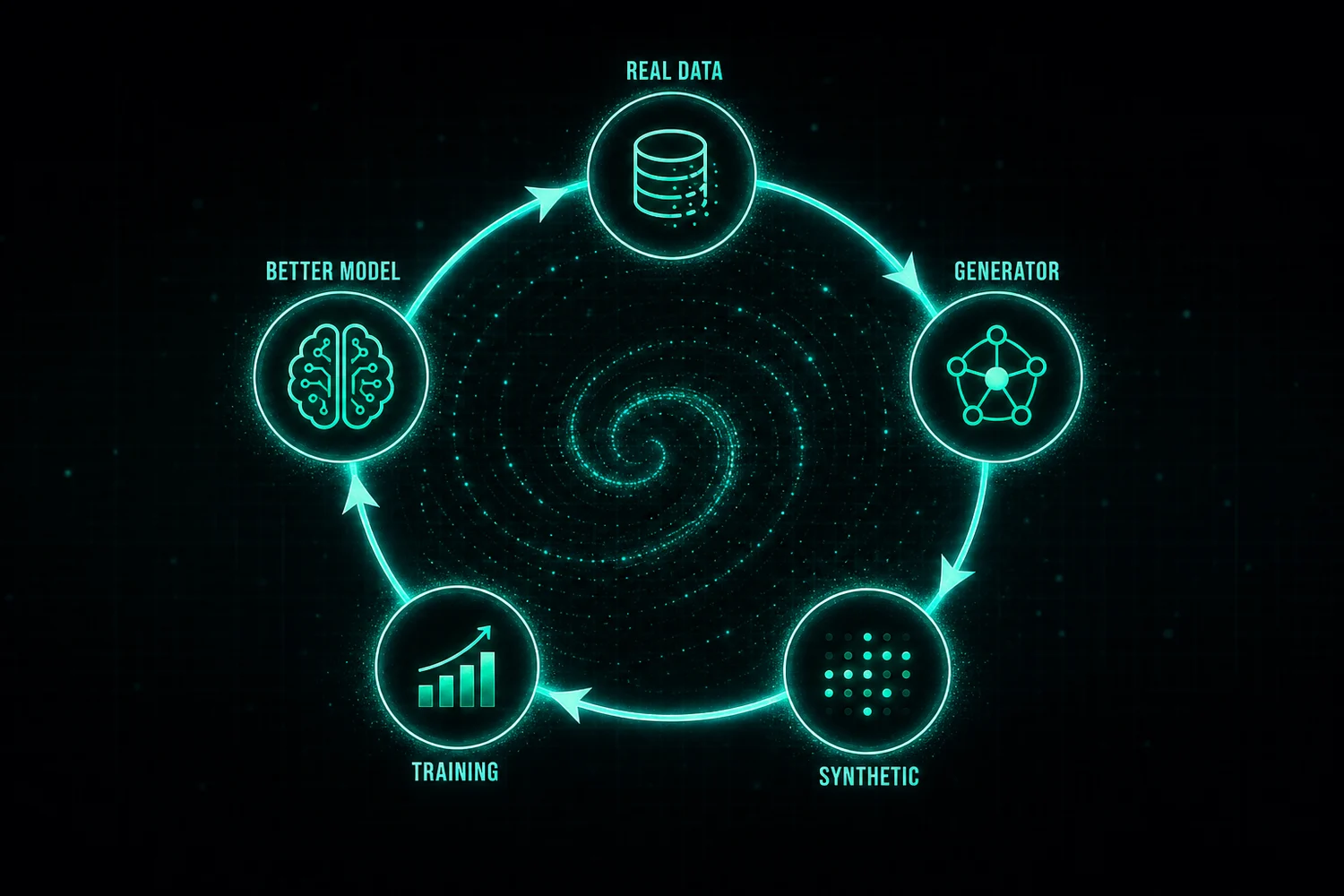
Quality and Diversity Concerns
The hard part of synthetic data is quality. AI-generated text isn't automatically as varied, creative, or grounded as the human-written kind. Lean on it too heavily and a model can turn into an echo chamber, replaying patterns it has already seen instead of producing anything new. That's the core of model collapse: successive generations of models trained on synthetic data degrade in quality and diversity.
The risk is real, not theoretical. A 2024 study in Nature showed that models trained recursively on purely synthetic data lose performance and diversity over multiple generations. (You'll sometimes see this pinned to a tidy "3-5 iterations" figure, but the research doesn't fix a single threshold, so read that as a rough illustration rather than a hard number.) The better news is that collapse can be headed off. Mixing in real data works, even a small fraction of genuine data prevents the slide, alongside generation methods that push for diversity and quality filters that strip out repetitive or weak examples.
The leading labs have built serious quality-control pipelines around this. Anthropic's work on Constitutional Classifiers, for instance, trains filters on synthetically generated data checked against a written constitution, so only examples that clear safety and quality bars make it through. OpenAI's CriticGPT is a related idea from a different angle: a specialised model that critiques other models' outputs to help human trainers catch errors during reinforcement learning. The labs argue these methods have lifted synthetic data quality close to human levels, though "indistinguishable on standard evaluations" is the kind of claim that tends to outrun the published benchmarks, so it's worth treating as a vendor pitch rather than settled fact.
Legal and Privacy Advantages
Synthetic data carries real legal and privacy upsides over scraped human content. Train on data the model invented and there's no original work sitting underneath to infringe, no real person whose details might leak, and far less of the licensing uncertainty that has triggered lawsuits against major labs. "Eliminates" overstates it, synthetic data spun out of a model that was itself trained on copyrighted work can still carry derivative-work and memorisation risks, and legal scholars are still arguing the point, but the direction of travel clearly favours lower exposure.
That's pulling regulated industries in. Healthcare firms use synthetic patient records to train diagnostic models without touching real medical files. Financial services use synthetic transaction data to train fraud detection. And consumer AI companies increasingly treat synthetic training data as a hedge against the next round of copyright litigation.