

A deep dive into Subquadratic's bold claims of 1,000x compute reduction, sub-quadratic sparse attention, and whether a Miami startup has achieved what the AI giants could not.
Introduction: The Attention Problem That Has Haunted AI
Every token compared against every other token. That is the simple, elegant, and fundamentally limiting principle upon which the entire modern AI industry has been built. Since the seminal "Attention Is All You Need" paper in 2017, the transformer architecture has powered everything from ChatGPT to Claude, from Gemini to DeepSeek. Yet hidden within that elegance lies a mathematical time bomb: quadratic scaling. As context length doubles, compute quadruples. As context length increases tenfold, compute explodes one hundred-fold. This single property has shaped the economics of AI, determined what is possible, and spawned an entire industry of workarounds - from retrieval-augmented generation (RAG) to chunking strategies to multi-agent orchestration.
Enter SubQ. On 5 May 2026, a thirteen-person startup based in Miami called Subquadratic emerged from stealth with $29 million in seed funding and a claim so audacious it immediately divided the AI community: they had built the first frontier large language model to escape quadratic attention entirely. Their model, SubQ 1.1 Small, reportedly handles up to 12 million tokens in a single pass - twelve times what the model was primarily trained on - and reduces attention compute by nearly 1,000x compared to dense transformers.
If true, this represents the most significant architectural shift since the transformer itself. If false, it risks becoming the biggest credibility crisis in AI since the field's various overpromise cycles. This article examines the claims, the architecture, the benchmarks, the scepticism, and what it all means for the future of artificial intelligence.
The Quadratic Scaling Problem: Why Context Windows Have Hit a Wall
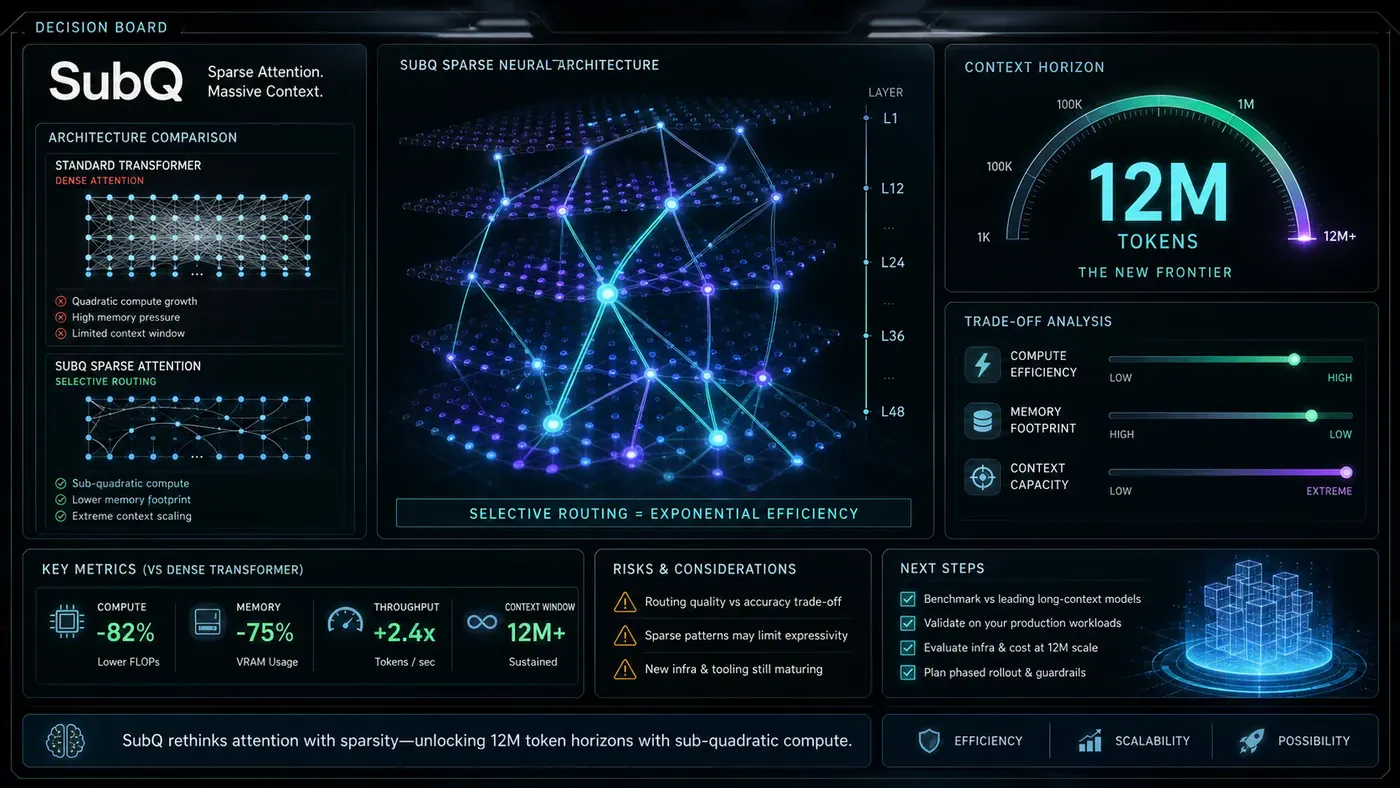
Standard transformer models use dense attention: every token attends to every other token. For a sequence of length *n*, this creates *n²* pairwise interactions. A 1,000-token prompt requires one million comparisons. A one-million-token prompt requires one trillion. This is why frontier models like GPT-5.5, Claude Opus 4.8, and Gemini 3.1 Pro max out at roughly one million tokens - and why using even that much context is prohibitively expensive.
The consequences ripple through the entire AI stack. Enterprise developers cannot feed an entire codebase into a model; they must chunk it and retrieve relevant snippets. Financial analysts cannot load complete document collections; they must summarise and filter. Legal teams cannot reason across entire contracts in one pass. As Subquadratic's CEO Justin Dangel noted in the launch post, "developers and investors spend more of their time and money on workarounds than on the problem itself."
What Is SubQ? Breaking Down the Architecture
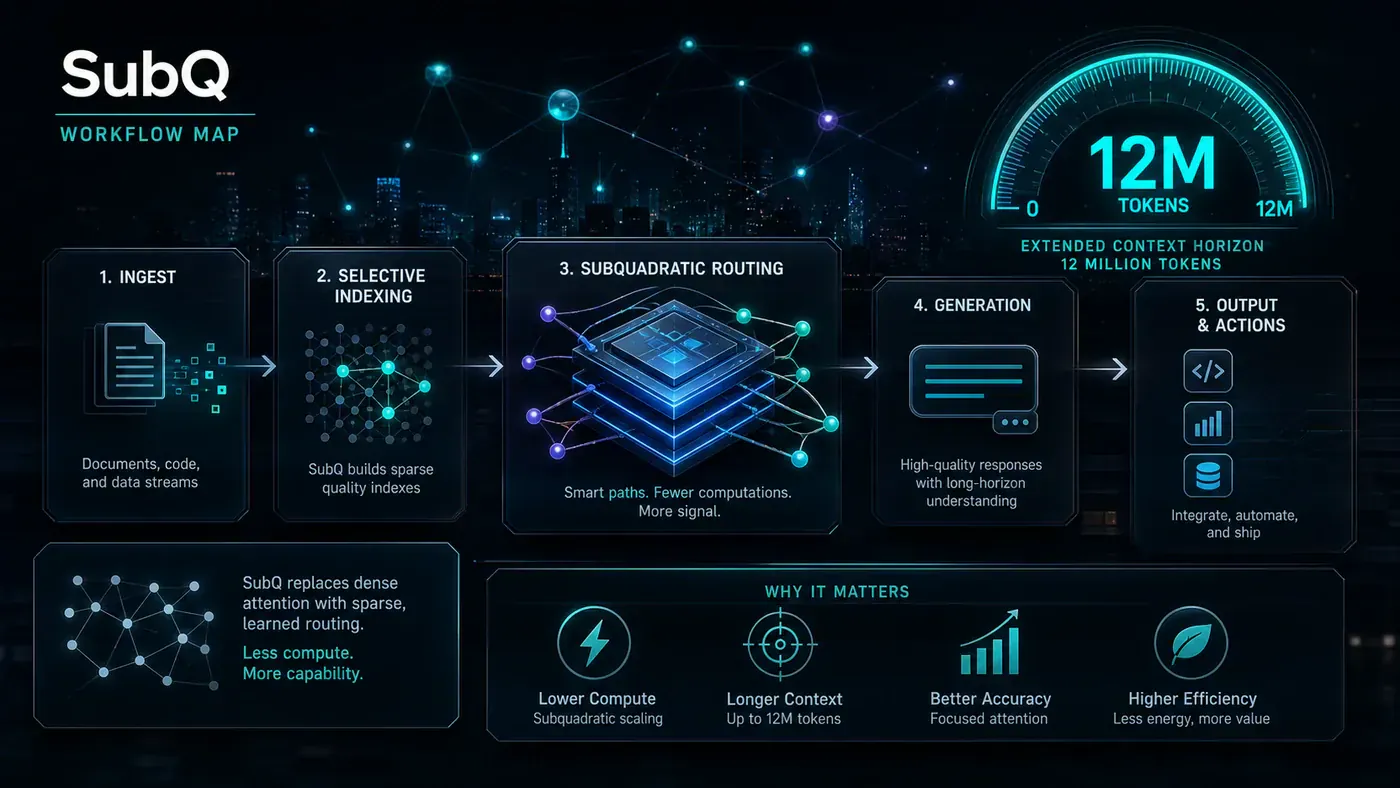
SubQ is built on Subquadratic Sparse Attention, or SSA. Rather than computing attention across all token pairs, SSA uses content-dependent routing to select only the most relevant tokens for each position. It computes similarity scores between tokens - analogous to standard query-key attention scoring - and retains only the top *k* matches. This changes the complexity from O(n²) to approximately O(n·k), where *k* is held small relative to *n*.
The technical report reveals that SSA combines learned sparse selection with Heavily Compressed Attention (HCA). Where sparse selection retrieves relevant token positions, HCA compresses distant portions of the sequence and performs dense attention over the compressed representation. Together, these mechanisms provide information at multiple contextual scales without computing dense attention over the full sequence.
Critically, SSA's token selection is content-dependent rather than position-dependent. The model does not simply attend to nearby tokens - a common pattern in earlier sparse approaches - but can route attention to relevant tokens anywhere in the sequence. This, Subquadratic argues, is what enables generalisation far beyond the training context length.
The 12 Million Token Claim and the Evidence
To put 12 million tokens in perspective: it is approximately 9 million words, or roughly 120 full-length novels. No other frontier model has been tested at this scale.
SubQ's technical report, independently verified by Appen, documents needle-in-a-haystack retrieval at 100% accuracy for 1 million and 2 million tokens, with 98% accuracy sustained at both 6 million and 12 million tokens. On the RULER benchmark - a 13-task suite covering multi-hop variable tracing, frequency extraction, and aggregation - the model scores 99.12% at 128,000 tokens.
The generalisation behaviour is perhaps the most intriguing finding. SubQ 1.1 Small was trained predominantly at 1 million tokens, with additional training at 2 million. Yet its retrieval held at 12 million tokens - twelve times its primary training length - while attending to only 0.13% of token pairs. As the technical report notes, "This generalisation is a direct consequence of SSA routing attention based on content relevance rather than fixed positional patterns."
Benchmarks: Trading Blows with Frontier Models
Beyond raw context length, SubQ 1.1 Small's benchmark performance reveals a model competitive with mid-tier frontier offerings at a fraction of the cost.
On LiveCodeBench v6 - a continuously updated competitive programming benchmark - SubQ achieves 89.7% pass@4, within striking distance of GPT-5.5 (92%) and Claude Opus 4.8 (92.2%), and ahead of Sonnet 4.6 (88.9%). On GPQA Diamond, a graduate-level science benchmark, SubQ reaches 85.4%, sitting below Sonnet 4.6 (87.5%) but comfortably above smaller models like Haiku 4.5 (67.2%).
On AutomationBench Finance - a long-horizon agentic benchmark - SubQ scores 13%, approaching Opus 4.8 (16%) and substantially outperforming Sonnet 4.6 (8%). The absolute scores remain low across all models, reflecting the benchmark's difficulty, but SubQ's positioning suggests its long-context training transfers to extended reasoning.
Efficiency claims are striking. At 1 million tokens, the company reports 64.5x less compute than dense attention and 56x faster inference than FlashAttention-2 (966 ms versus 54,164 ms on an H100). A RULER evaluation reportedly costing ~$8 on SubQ would cost roughly $2,600 on Claude Opus at the same context length.
How SubQ Differs from Previous Sparse Attention Approaches
Subquadratic is not the first to attempt sub-quadratic attention. Longformer and BigBird introduced fixed sparse patterns - local windows plus global tokens - but these are not content-dependent and struggle on dynamic retrieval tasks. Mamba and the state space model family abandon attention entirely for recurrent state updates, achieving linear scaling but historically underperforming on precise long-range retrieval.
DeepSeek V4 introduced CSA, which uses content-dependent routing similar to SSA, but continues to scale quadratically due to its HCA compression component. Magic.dev's LTM-2-Mini claimed 100 million token contexts in 2024 - yet as industry observers note, "we still haven't seen evidence anyone outside of Magic.dev is using this model."
SubQ's differentiator, if its claims hold, is threading the needle: content-dependent selection that preserves precise retrieval while achieving genuinely linear scaling. The company acknowledges this is ongoing research, not a solved problem. The technical report states that "the mechanism by which SSA meets these requirements is outside the scope of this report" on certain details - a gap that has fuelled scepticism.
The Scepticism: What Critics Are Saying
Within hours of launch, the AI community split into camps. The "AI Theranos" comparison was raised by multiple commentators as a warning about the gap between demo and deployment.
Several concerns have emerged. First, benchmark selection is narrow: three primary tests focused on long-context retrieval and coding - the exact areas SubQ is designed to excel at. Broader evaluations across mathematics, multilingual performance, and safety have not been published.
Second, there is a notable research-to-production gap on MRCR v2, a multi-needle retrieval benchmark. SubQ's research result was 83%, but the production model scored 65.9% - a 17-point drop that remains unexplained.
Third, scaling claims have raised eyebrows. Marketing materials reference O(1)-like scaling while the technical report describes linear scaling. Critics note that at true O(1) or O(log n) scaling, one might expect windows far exceeding 12 million tokens.
Fourth, the CTO confirmed post-launch that SubQ builds on open-source base models rather than training from scratch. This is pragmatic but means the core innovation lies in the attention mechanism, not the base model.
Real-World Use Cases: What 12 Million Tokens Enables
If SubQ's capabilities translate to production, the implications are substantial:
Software Engineering at Scale: Current coding agents cannot see entire codebases. With 12 million tokens - roughly 500,000 to 1 million lines of code - an entire repository loads in one pass, enabling architecture-level reasoning and cross-file refactoring without orchestrated multi-step processes.
Financial Analysis and Due Diligence: Earnings reports, filings, and contracts are meaningful only in combination. SubQ claims to reason across complete document collections directly rather than processing documents in isolation.
Legal and Contract Work: Contracts define terms early, qualify them hundreds of pages later, and carve out exceptions thousands of pages after that. A model holding the entire document can reason across it holistically.
Persistent Agent State: Long-running agentic workflows require coherent state across extended sessions. A 12 million token window provides room for both working context and full history.
Training and the Iteration Advantage
One of SubQ's most underappreciated claims concerns training, not inference. The company reports running over one hundred experiments across six to seven model generations to balance long- and short-context capabilities. That volume of long-context experimentation, they argue, was only possible because SSA made million-token training runs practical.
The recipe involved starting with an open-weight frontier model, replacing dense attention with SSA, and performing staged context extension through 262K, 512K, 1M, and 2M tokens, followed by roughly one trillion tokens of continued pretraining on long artifacts: books, documents, and repository-scale code. The strongest lever for improving retrieval, they found, was long-context continued pretraining - made feasible by SSA's efficiency.
If efficient attention architectures make long-context experimentation affordable, the pace of innovation could accelerate dramatically. The bottleneck shifts from compute availability to research creativity.
Limitations and Honest Assessment
SubQ's technical report acknowledges significant limitations. Balancing short- and long-context capability proved delicate: gains in one frequently came at the expense of the other. Benchmark scores diverged from deployment-shaped behaviour more than expected. MRCR v2 optimisation did not reliably translate to better real-world performance - checkpoints that scored well on MRCR often "felt worse in use."
The company also notes that evaluation scope remains limited. Results were independently verified by Appen, but broader evaluations have not been conducted. The model is not yet publicly available; access remains waitlist-only. Hardware requirements for serving 12 million token contexts - and latency at that scale - remain unanswered questions.
The Competitive Landscape
SubQ enters a market where context windows are expanding rapidly. As of mid-2026, Claude Opus 4.8, GPT-5.5, and Gemini 3.1 Pro offer ~1 million tokens. Grok 4 Fast reaches 2 million. Meta's Llama 4 Scout claims 10 million on a single GPU. Magic.dev's LTM-2-Mini claimed 100 million in 2024 - with limited evidence of adoption.
The difference lies not in window size but in cost and scaling. Standard models maintain quadratic attention costs, making long-context usage expensive even when technically possible. SubQ's claim is that it breaks that cost curve - making long-context processing not just possible but economical.
Whether this overcomes the ecosystem effects of incumbent providers - deeply integrated into enterprise workflows, developer tools, and cloud platforms - remains to be seen. Architecture advantages do not automatically translate to market adoption, particularly when incumbents can replicate innovative approaches.
Conclusion: Breakthrough or Mirage?
Three weeks after launch, SubQ remains one of the most intriguing and contested developments in AI. Independently verified benchmarks lend credibility to the core claims: near-perfect retrieval at unprecedented lengths, competitive coding and reasoning performance, and efficiency gains that alter long-context economics. The architecture - content-dependent sparse attention with linear scaling - is theoretically sound and builds on years of research.
Yet significant questions remain. The narrow benchmark selection, the research-to-production gap, undisclosed SSA routing details, reliance on open-source base models, and absence of public availability for independent testing all mean final judgement must wait.
What SubQ has already accomplished, regardless of the ultimate verdict, is demonstrating that the transformer monopoly on frontier AI is not unbreakable. The company has made sub-quadratic attention a credible contender, shifted the conversation from incremental context expansion to architectural reform, and shown that small teams with focused research can challenge trillion-dollar incumbents' assumptions.
The next few months will be decisive. As SubQ deploys with design partners and broader access becomes available, the community will learn whether 12 million tokens of genuinely usable context is a new reality - or another demo that dazzled before it delivered.
Helpful Resources
- SubQ Official Website: https://subq.ai/ - Homepage of Subquadratic with product information and early access signup
- SubQ 1.1 Small Product Page: https://subq.ai/subq-1-1-small - Detailed product information and specifications
- SubQ 1.1 Small Technical Report: https://subq.ai/subq-1-1-small-technical-report - Full technical details on architecture, benchmarks, and training
- SubQ 1.1 Small Model Card (PDF): https://subq.ai/docs/subq-1-1-small-model-card.pdf - Comprehensive model documentation
- Independent Verification by Appen: https://www.appen.com/whitepapers/subquadratic-preview-model-benchmark-evaluation - Third-party benchmark assessment
- SubQ Launch Announcement: https://subq.ai/introducing-subq - Original blog post from 5 May 2026
- How SSA Works: https://subq.ai/how-ssa-makes-long-context-practical - Technical explanation of Subquadratic Sparse Attention
- DataCamp Analysis: https://www.datacamp.com/blog/subq-ai-explained - Independent breakdown of claims, architecture, and caveats
- Medium Deep Dive: https://medium.com/@candemir13/subq-what-actually-changed-and-whats-vendor-run-4fb63d4fb11b - Analysis of changes between launch and 1.1 Small
- The AIGRID Community (Skool): https://www.skool.com/the-aigrid-community-1726 - Free AI learning community
- The AIGRID Newsletter: https://aigrid.beehiiv.com/subscribe - AI updates and analysis
- AGI Preparedness Guide: https://theaigrid.kit.com/agi - Free guide from TheAIGRID
- TheAIGRID on Twitter/X: https://twitter.com/TheAiGrid - Social media updates


