Introduction: Why This One Belongs on the Watchlist
Most "breakthrough" model announcements are bigger checkpoints on the same transformer curve. SubQ, from startup Subquadratic, claims to replace dense attention with a learned sparse attention mechanism that scales linearly with context length. If the claims hold, long-context inference economics change materially, and tasks that currently need retrieval pipelines and chunking could collapse into a single prompt. The reason it matters for AI Kick Start readers is practical: this is not just another launch to admire from a distance. It changes how founders, operators, and technical teams should think about AI Implementation work over the next few months. The source transcript repeatedly centres on Subquadratic Sparse Attention, 12-million-token context windows and long-context retrieval, with the video framing the topic as a practical workflow rather than a detached product announcement. That is the useful lens. The video is worth treating as implementation intelligence: what should be tested, what should be ignored for now, and what should become part of a repeatable operating system. For Australian small businesses and technical teams, the right question is not "is this impressive?" The right question is "where does this reduce friction without creating a larger governance, security, or maintenance problem?"
What the Video Actually Shows
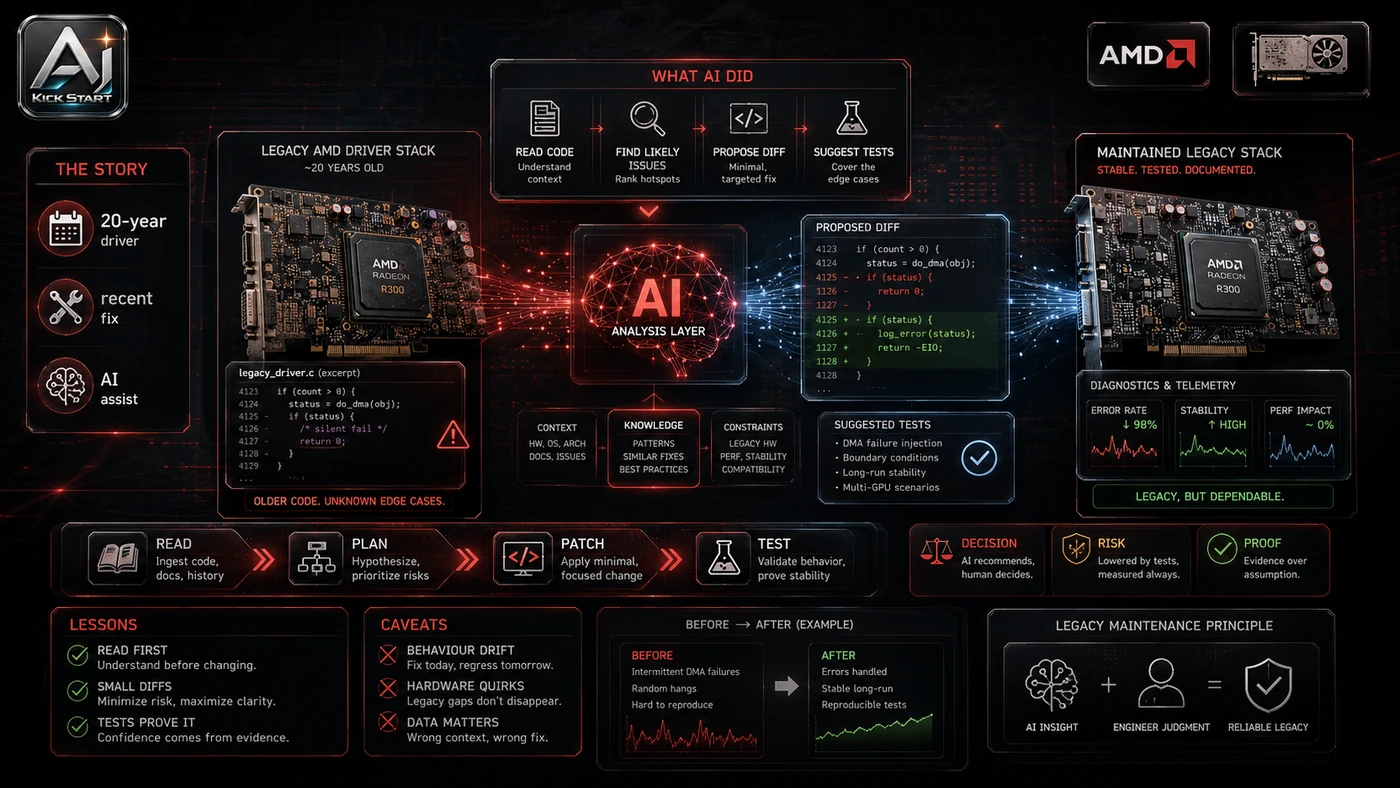
The core pattern is simple: load the entire artifact into one context window, replace dense attention with sparse attention, and validate retrieval fidelity before trusting the single-prompt workflow. In practice, that means the update sits inside a broader shift from isolated AI prompts to managed systems. A tool, model, or method only becomes valuable when it has clear inputs, a measurable output, a review path, and a way to repeat the result next week. The video's most useful signal is the workflow shape. The moving parts can be summarised as: Long-context source material Sparse attention mechanism Single-prompt reasoning Retrieval benchmark loop That is the level at which teams should evaluate it. A demo can be entertaining, but a workflow must survive messy source files, staff handoff, data boundaries, and real deadlines.

The Implementation Pattern
The first implementation lesson is to narrow the scope. Start with one long-context task your team already does badly or expensively. Broad adoption is usually where AI systems fail first because nobody knows which decision the tool is allowed to make and which decision still belongs to a human. The second lesson is to create a test harness. Run the same task through your current stack and SubQ using identical prompts and success criteria. A useful harness does not have to be complicated. It can be a short brief, a fixed sample dataset, a few expected outputs, and one person responsible for judging whether the result is good enough. The third lesson is to capture the process. Document prompt and context boundaries, test at increasing context lengths, and record where quality degrades. When the process is documented, it can become a reusable skill, checklist, prompt pack, repo pattern, or operating procedure. When it is not documented, the team is back to improvising in chat.
Research Update: What To Correct
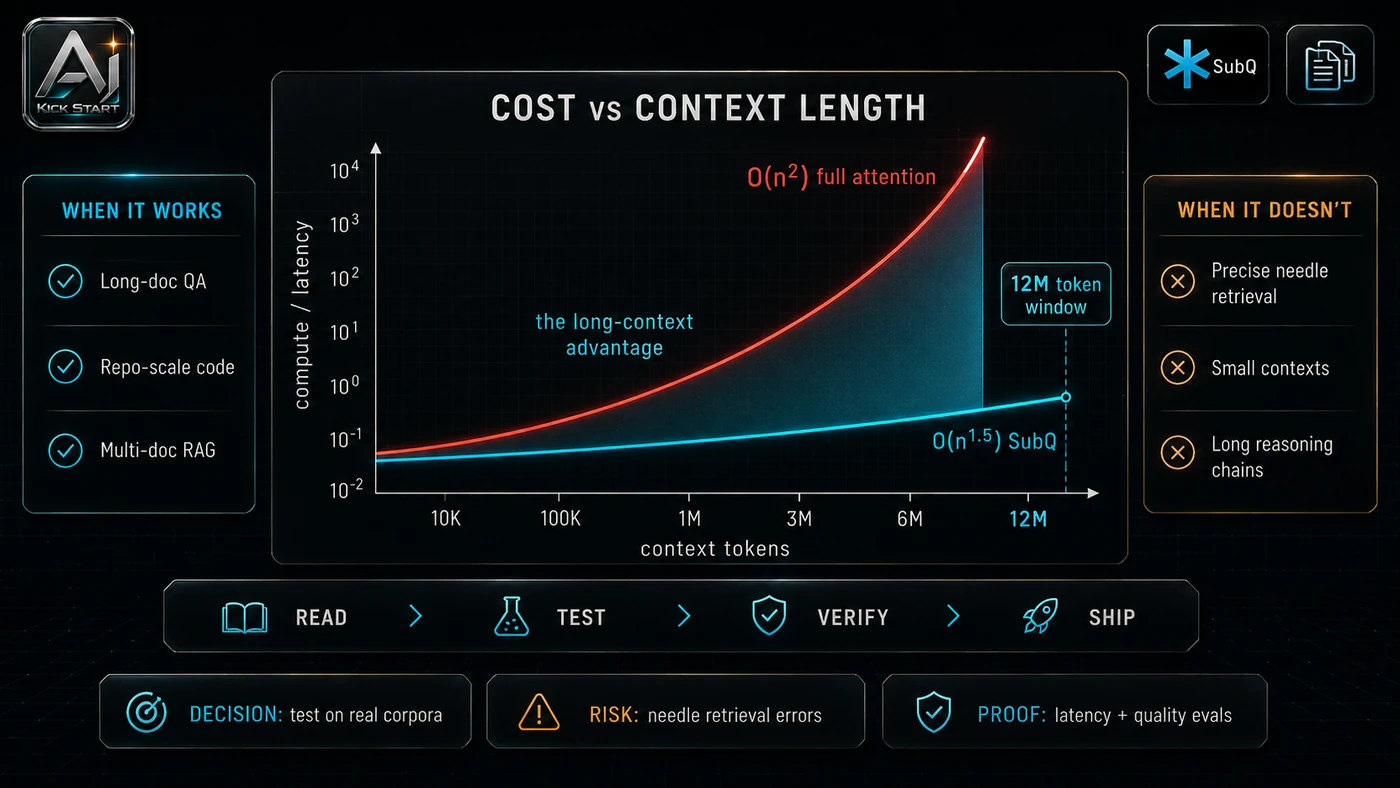
This update adds a current-source pass rather than treating the original video summary as enough. The important corrections are the product surface, plan or pricing constraints, and what should be verified before a team depends on the workflow. SubQ is not the first long-context model announced, though it appears to be the first with a technical report and third-party benchmarks for a 12-million-token sparse-attention model. The model is not trained from scratch; it reportedly starts from existing open-weight frontier model weights and replaces dense attention with SSA. The "1,000× less compute" figure is an attention-mechanism comparison at 12 million tokens, not a whole-model cost reduction; at 1 million tokens the reported FLOP and wall-clock savings apply to the attention layer, not the whole model. The benchmark set is narrow, with strong results on long-context retrieval and coding but limited visibility on general reasoning, safety, and short-context performance. Appen verified the benchmarks, but the evaluation was commissioned by Subquadratic, so it is a vendor-paid engagement rather than independent lab reproduction. The video also conflates two releases: the May 2026 "SubQ 1M-Preview" and June 2026 "SubQ 1.1 Small" are different milestones, with the stronger benchmark figures belonging to 1.1 Small.
Practical Setup and How-To
The useful next step is a controlled pilot with a named owner, fixed inputs, a measurable output, and a review point. Use the sequence below as the first implementation path before expanding the workflow. Request early access at subq.ai/request-early-access and expect a waitlist and a design-partner conversation rather than instant API keys. Audit your OpenAI-compatible stack, since SubQ exposes OpenAI-compatible endpoints with streaming and tool use, so existing /chat/completions code should port with a base-URL and model-name change. Prepare a test harness before the keys arrive by picking one long-context task your team already does badly or expensively. Build a paired evaluation by running the same task through your current stack and SubQ using identical prompts and success criteria. Start with read-only or low-stakes outputs and do not connect SubQ to production systems or customer-facing workflows until the evaluation is complete.
Pricing, Access, and Comparison Notes
Pricing and access should be checked at implementation time because AI products change quickly. The safer decision is to compare the tool against the job-to-be-done, not against launch hype. Public per-token pricing has not been released. The video cites a reported $8 cost on SubQ versus roughly $2,600 on Claude Opus for the same long-context evaluation, but that is a benchmark-run anecdote, not a published price list. Until Subquadratic publishes token rates, any total-cost-of-ownership analysis is provisional. SubQ 1.1 Small leads on context length and long-context retrieval, while Claude Opus 4.8 and GPT-5.5 lead on general availability and broader benchmark strength. The practical comparison is not "is SubQ better than Claude or GPT?" It is "for our specific long-context task, is SubQ good enough at a meaningfully lower total cost?" Access Plan, preview status, region, account type, admin controls, and rate limits. Cost Subscription, credits, API tokens, retries, hardware, review time, and support burden. Fit Workflow reliability, data handling, output quality, observability, and human approval needs.
Implementation Notes for Teams
For AI Kick Start readers, this is the production filter: keep the first rollout narrow, make the evidence visible, and do not let the tool cross a business boundary until the review model is clear. Scope the pilot tightly to one workflow, one team, and one success metric. Keep a human review gate, because long-context retrieval can look correct while quietly missing a contradictory clause or dependency. Watch for context-window enthusiasm, since just because you can fit 12 million tokens does not mean you should; longer contexts increase latency and cost and can amplify positional bias. Record everything, because sparse attention is less interpretable than dense attention. Plan a rollback to your existing RAG or chunking stack if SubQ does not meet the bar. Check data residency and compliance, since Subquadratic is a US startup without published SOC 2, ISO, or data-residency details at the time of writing.
Screenshot and Visual Guidance
The second inline image for this article should make the implementation concrete: A clean comparison chart showing dense attention FLOPs curving upward quadratically while SSA stays nearly flat, paired with a retrieval table scoring needle-in-a-haystack at 1M, 2M, 6M, and 12M tokens. If the team is documenting a real rollout, capture setup screens, before/after outputs, permission settings, cost meters, and review evidence rather than decorative screenshots. The FLOPs chart sets stakeholder expectations for attention-layer mechanics, not whole-pipeline cost; the retrieval table is the benchmark to test against in your own evaluation.
Where It Fits for Real Teams
For founders, the opportunity is speed with evidence. This kind of workflow can reduce the time between idea and first useful output, but it should still produce artefacts that a customer, manager, or developer can inspect. For operators, the value is consistency. If the same task is done slightly differently every time, AI can either make the inconsistency worse or help standardise the path. The difference is whether the workflow has rules, examples, and review checkpoints. For technical teams, the value is leverage. A strong setup lets agents, models, or creative systems take on repeatable work while engineers keep control over architecture, security, deployment, and final judgement. The practical fit is strongest when the task has clear source material, a known output format, and a low-cost way to verify quality. It is weaker when the task is vague, politically sensitive, legally risky, or dependent on facts that cannot be checked. SubQ suits teams with code-heavy, document-heavy, or long-history workflows where retrieval fidelity matters. It is a poor fit for general chatbots, multimodal applications, real-time low-latency tasks, or anything requiring public weights, published safety evaluations, or strict vendor compliance.
Trade-offs and Risks
The main risk is vendor lock-in. Closed weights and a proprietary sparse-attention architecture mean you cannot self-host or fine-tune if the API changes or the company pivots. That risk can be managed, but only if it is named before the workflow becomes normal. A second risk is the benchmark-reality gap. AI systems often look better in a screen recording than they feel inside a production workflow. The test is whether the result is repeatable when the source material changes, the operator changes, and the deadline is real. Needle-in-a-haystack and RULER are clean tests; real documents are messier: scanned PDFs, inconsistent formatting, embedded tables, and cross-references that span hundreds of pages. A third risk is sparse attention blind spots in short-context performance and multi-fact reasoning across loosely related passages, plus support, roadmap, governance, and compliance gaps from a seed-stage US startup. This is why AI Kick Start generally recommends a staged rollout: sandbox first, internal use second, customer-facing deployment last.
The Next Sensible Test
The next sensible test is a small controlled implementation. Pick one workflow, one owner, one expected output, and one acceptance check. Run it twice. If the second run is easier than the first, the pattern is worth keeping. Do not judge the workflow by the best possible demo. Judge it by the worst acceptable production case. Pick a task where the current cost or friction is measurable - a contract review that takes a lawyer half a day, a code review that spans twenty files, or a support investigation that requires reading a month of ticket history. Run it through SubQ, run it through your existing model, and compare retrieval accuracy, latency, cost, and validation time. If SubQ wins cleanly, expand to a second workflow. If it does not, you have a documented baseline and no architectural regret. Ask: what happens when the source file is incomplete, the tool is unavailable, the output is wrong, or a staff member needs to explain the result to a customer? If those answers are clear, this belongs in the roadmap. If they are not, it belongs in the lab until the operating model catches up.