

Introduction: Why This One Belongs on the Watchlist
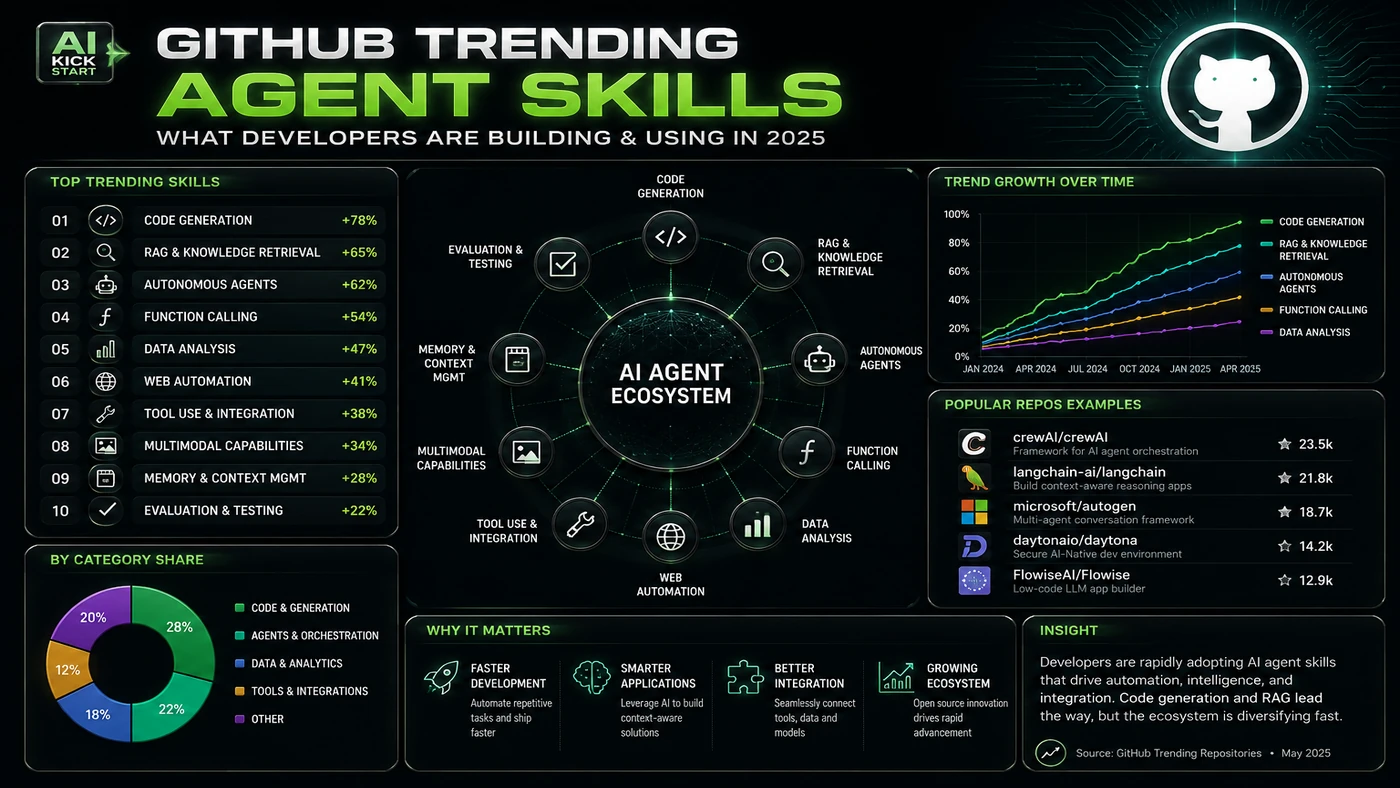
Hyperautomation Labs' rundown of the top ten trending GitHub repositories (as of 23 June 2026) is less a product review than a market memo. Half the list is reusable capability packs for coding agents: skills from Matt Pocock and Addy Osmani, a memory layer for codebases, live-web access, and a security scanner from NVIDIA built specifically to inspect those skills. The reason it matters for AI Kick Start readers is practical: this is not just another launch to admire from a distance. It changes how founders, operators, and technical teams should think about AI Engineering work over the next few months. The source transcript repeatedly centres on agent skills, codebase memory and live-web adapters, with the video framing the topic as a practical workflow rather than a detached product announcement. That is the useful lens. The video is worth treating as implementation intelligence: what should be tested, what should be ignored for now, and what should become part of a repeatable operating system. For Australian small businesses and technical teams, the right question is not "is this impressive?" The right question is "where does this reduce friction without creating a larger governance, security, or maintenance problem?"
What the Video Actually Shows
The core pattern is simple: assemble your agent from composable parts instead of prompting it from scratch every session. The video ranks repositories by weekly star momentum, not total stars, and the host warns that star counts can be gamed. The dominant theme is agent skills. The top repo, mattpocock/skills, is one engineer's .claude/skills directory; around it sit addyosmani/agent-skills, DeusData/codebase-memory-mcp, Panniantong/Agent-Reach, and NVIDIA/SkillSpector. The remaining repos are creative alternatives: Voicebox, Penpot, OpenCut, OpenMontage, and Google's TimesFM. In practice, that means the update sits inside a broader shift from isolated AI prompts to managed systems. A tool, model, or method only becomes valuable when it has clear inputs, a measurable output, a review path, and a way to repeat the result next week. The video's most useful signal is the workflow shape. The moving parts can be summarised as: Skill pack Memory layer Web access Security scan. That is the level at which teams should evaluate it. A demo can be entertaining, but a workflow must survive messy source files, staff handoff, data boundaries, and real deadlines.

The Implementation Pattern
The first implementation lesson is to narrow the scope. Start with one project and one agent, and do not install every skill on the list. Broad adoption is usually where AI systems fail first because nobody knows which decision the tool is allowed to make and which decision still belongs to a human. The second lesson is to create a test harness. Keep the agent's tool permissions small. A useful harness does not have to be complicated. It can be a short brief, a fixed sample dataset, a few expected outputs, and one person responsible for judging whether the result is good enough. The third lesson is to capture the process. Document how the skill is installed, activated, and reviewed, and decide where generated outputs live before they become invisible technical debt. When the process is documented, it can become a reusable skill, checklist, prompt pack, repo pattern, or operating procedure. When it is not documented, the team is back to improvising in chat.
Research Update: What To Correct
This update adds a current-source pass rather than treating the original video summary as enough. The important corrections are the product surface, plan or pricing constraints, and what should be verified before a team depends on the workflow. "Fastest-growing" is momentum, not size: mattpocock/skills had roughly 146,500 stars at the time of writing and was created in February 2026. Skills are not brand new: Anthropic announced Claude Skills in October 2025 and published an open standard in December 2025; what is new is the rate at which quality packs are shared. Agent-Reach is not generic web search; it is platform-specific adapters (Twitter/X, Reddit, YouTube, Bilibili, Xiaohongshu, LinkedIn, RSS, GitHub), each with its own configuration, cookie, and rate-limit surface. TimesFM is "zero training" for inference, not zero setup. Penpot is production-grade, but migrating from Figma is a workflow migration, not a one-click swap. OpenMontage and OpenCut are early: useful for experiments, not client deadlines.
Practical Setup and How-To
The useful next step is a controlled pilot with a named owner, fixed inputs, a measurable output, and a review point. Use the sequence below as the first implementation path before expanding the workflow. Audit your current agent workflow and map pains to skill categories. Pick a starter pack: for Claude Code and Codex users, install mattpocock/skills with npx skills@latest add mattpocock/skills and run /setup-matt-pocock-skills; for explicit lifecycle gates, use addyosmani/agent-skills. Add memory for large repos with codebase-memory-mcp, restart the agent, and say "index this project". Add live web access only where justified through Agent-Reach, enabling only the adapters the workflow genuinely needs. Scan before you trust by passing every external skill through NVIDIA's SkillSpector with uv tool install git+https://github.com/NVIDIA/skillspector.git and skillspector scan ./my-skill/ --no-llm.
Pricing, Access, and Comparison Notes
Pricing and access should be checked at implementation time because AI products change quickly. The safer decision is to compare the tool against the job-to-be-done, not against launch hype. The repos themselves are open source and free under permissive licences (mostly MIT or Apache 2.0), so the real cost is the underlying agent usage and the time to review, customise, and govern the skills. Claude Code is free to install but heavy usage pushes most teams to a paid Anthropic plan, while Cursor, Codex CLI, and Windsurf have their own pricing. Compare a curated skill pack, a custom internal skill, and a managed-agent approach only after the v0 task proves repeatable. Access Plan, preview status, region, account type, admin controls, and rate limits. Cost Subscription, credits, API tokens, retries, hardware, review time, and support burden. Fit Workflow reliability, data handling, output quality, observability, and human approval needs.
Implementation Notes for Teams
For AI Kick Start readers, this is the production filter: keep the first rollout narrow, make the evidence visible, and do not let the tool cross a business boundary until the review model is clear. Pin versions rather than installing @latest in production; fork or pin to a commit hash. Keep a skill registry that lists what is installed, why, who approved it, and its risk level. Project-scope where possible by preferring .claude/skills/ inside a repo over global ~/.claude/skills/, so the skill set is versioned with the project. Run SkillSpector in CI and block skills that fail the baseline. Review activation descriptions so vague descriptions do not load too often and overly narrow ones do not load too rarely. Set git guardrails so the team knows what commands are intercepted, and document the handoff so generated ADRs or PRDs actually get read.
Screenshot and Visual Guidance
The second inline image for this article should make the implementation concrete: a clean skill-registry table showing the skill name, approved owner, licence, risk level, pinned version, and CI scan result next to a project-local .claude/skills/ folder. If the team is documenting a real rollout, capture setup screens, before/after outputs, permission settings, cost meters, and review evidence rather than decorative screenshots.
Where It Fits for Real Teams
For founders, the opportunity is speed with evidence. Small product teams can standardise code review, PRDs, and testing without a senior engineer on every task. For operators, the value is consistency. Agencies and consultancies can ship project-local skills that encode client conventions and handoff rituals. For technical teams, the value is leverage. Internal platform teams can publish guardrail skills (security, compliance, architecture) that downstream squads inherit while engineers keep control over architecture, security, deployment, and final judgement. Data teams should look at TimesFM for forecasting, but only with a benchmark against existing methods. Creative teams should keep Penpot on the roadmap as a Figma exit strategy, and treat OpenCut, OpenMontage, and Voicebox as experiments. The practical fit is strongest when the task has clear source material, a known output format, and a low-cost way to verify quality. It is weaker when the task is vague, politically sensitive, legally risky, or dependent on facts that cannot be checked.
Trade-offs and Risks
The main risk is over-broad tool access. A skill can read files, call tools, and execute commands with the agent's permissions, and that is both the point and the problem. That risk can be managed, but only if it is named before the workflow becomes normal. A second risk is skill bloat and unclear ownership. AI systems often look better in a screen recording than they feel inside a production workflow. The test is whether the result is repeatable when the source material changes, the operator changes, and the deadline is real. A third risk is shadow adoption and dependency drift. This is why AI Kick Start generally recommends a staged rollout: sandbox first, internal use second, customer-facing deployment last.
The Next Sensible Test
The next sensible test is a small controlled implementation. Pick one workflow, one owner, one expected output, and one acceptance check. Run it twice. If the second run is easier than the first, the pattern is worth keeping. Do not judge the workflow by the best possible demo. Judge it by the worst acceptable production case. Ask: what happens when the source file is incomplete, the tool is unavailable, the output is wrong, or a staff member needs to explain the result to a customer? If those answers are clear, this belongs in the roadmap. If they are not, it belongs in the lab until the operating model catches up.


