









Briefing
For most of the last two years, "multi-agent AI" was the sort of thing you read about in a research paper and quietly filed under "not yet". That has changed. By the middle of 2026, running several AI agents together on real work has stopped being an experiment and started looking like plumbing: unglamorous, increasingly standard, and worth getting right.
The shift matters for any business team weighing up where AI fits. One agent doing one job is easy to reason about. The moment you put several of them on the same project, you have to decide who is in charge, who talks to whom, and what happens when two of them disagree. Get that wrong and you do not get smarter software. You get a committee.
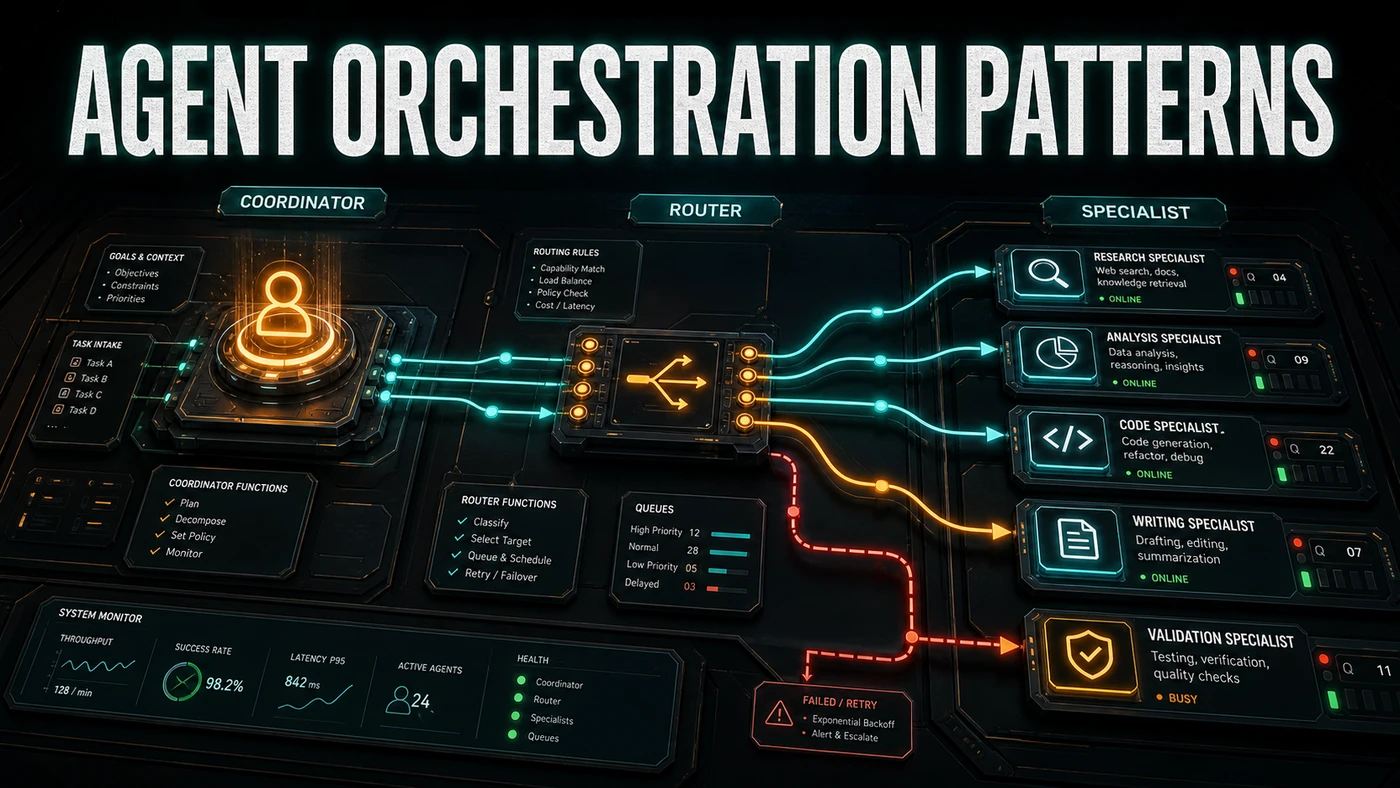
Three setups have become the common reference points for teams building this way: the Coordinator, the Router, and the Specialist. They are not competing products. They are different shapes for different jobs, and the useful skill is knowing which shape fits the work in front of you. Below is how each one behaves, where it earns its keep, and where it tends to fall over.
Pattern 1: The Coordinator
The Coordinator pattern runs one agent that holds the overall state and hands sub-tasks down to worker agents. It is the most straightforward way to wire up multiple agents, and it suits jobs that break cleanly into pieces.
Coordinator (maintains state, makes decisions)
├── Worker A (executes sub-task 1)
├── Worker B (executes sub-task 2)
└── Worker C (executes sub-task 3)Claude Code's Dynamic Workflows run this pattern out of the box. The coordinator (Claude Opus 4.8) keeps the task graph and parcels work out to specialist sub-agents. Hermes does something similar through its learning loop: the coordinator agent routes tasks based on skill signatures it has picked up over time.
Best for: Jobs that split cleanly into sequential or parallel steps. Migrations, refactors, generating documentation. Trade-off: The coordinator is one point of failure and one bottleneck. If it goes down, the whole thing stops with it.
Pattern 2: The Router
The Router pattern puts a middleman between incoming requests and the agents doing the work. The router reads each request, classifies it, and sends it to the right specialist. Unlike the coordinator, it holds no global state. It is stateless, which means it scales out sideways without much fuss.
Request -> Router (classifies and dispatches)
├── Code Agent (implementation tasks)
├── Test Agent (test generation and validation)
├── Review Agent (code review and quality)
└── Docs Agent (documentation generation)OpenClaw's sub-agent setup fits this shape. A parent agent passes messages to the right child agent. Worth a caveat here: OpenClaw's own multi-agent docs describe routing as binding-based (it matches on peer, thread, or role, with the most specific match winning) rather than the looser "content analysis" framing you sometimes see. OpenHuman reportedly takes a comparable line with its multi-model routing, sending different request types to different models.
Best for: High-volume settings with a wide mix of request types. Support bots, team assistants, CI/CD pipelines. Trade-off: With no shared state, individual agents can make choices that are sensible on their own but poor for the job as a whole.
Pattern 3: The Specialist
The Specialist pattern is the most involved of the three. Several agents, each with real depth in one domain, work together through shared protocols. Every specialist keeps its own memory, tools, and standards for judging good work. They hand off to each other, push back, and critique each other's output.
API Specialist <-> Database Specialist <-> Frontend Specialist
| | |
└------------------┴-----------------------┘
|
Integration TestsHermes builds this on its agentskills.io ecosystem. According to the project's own framing, specialist agents draw on independent Honcho memory models while sharing skill signatures, though the per-specialist memory detail leans more on interpretation than on documented behaviour. The idea is that each one owns its patch: the API specialist knows REST design, the database specialist knows query optimisation, and they meet in the middle through shared schemas and contracts.
Best for: Complex projects that need genuine depth across several areas at once. Platform engineering, full-stack work, system architecture. Trade-off: Heavy coordination cost. Specialists can disagree, and resolving that often needs a meta-coordinator sitting above them.
Choosing the Right Pattern
| Factor | Coordinator | Router | Specialist |
|---|---|---|---|
| Task complexity | Medium | Low-Medium | High |
| Request diversity | Low | High | Medium |
| Team size | Small | Large | Medium-Large |
| Domain depth | Medium | Low | High |
| Latency tolerance | High | Low | Medium |
| Coordination overhead | Medium | Low | High |
Implementation with tmux
If you live in the terminal, Claude Code can run agents across tmux panes, one agent per pane (this needs the CLAUDE_CODE_EXPERIMENTAL_AGENT_TEAMS flag set and tmux installed). The illustrative commands below show the three patterns side by side. Note that these are conceptual examples rather than shipping CLI commands: in practice, Claude Code's agent teams are started by describing your teammates in plain language, not via a claude multi-agent --pattern subcommand.
# Launch coordinator with 3 workers
claude multi-agent --pattern coordinator --workers 3
# Launch router with 4 specialists
claude multi-agent --pattern router --specialists code,test,review,docs
# Launch specialist pattern with 3 domain experts
claude multi-agent --pattern specialist --domains api,database,frontendAnti-Patterns to Avoid
- The recursive delegation spiral: Agent A hands off to Agent B, which hands off to Agent C, which hands back to Agent A. Cap it with a maximum delegation depth.
- The echo chamber: Specialists harden each other's mistakes because nobody checks the work from the outside. Add a dedicated critic agent.
- The coordination explosion: Too many agents talking, nobody working. As a rough heuristic, some practitioners suggest watching the share of effort spent on coordination and keeping it modest (one rule of thumb floated is under 25%), though this is a working guideline rather than an established benchmark.
- The single-model fallacy: Using one model for every role. Coordinators usually need a large model; workers often do not. Match the model to the job.
Multi-agent orchestration is not a numbers game. Piling on more agents does not buy you more capability. What pays off is the right agents, arranged sensibly, talking to each other in a way that suits the work. The three patterns here are well worn at this point, and the anti-patterns are the mistakes people keep making. Pick the one that matches your job, not the one that sounds most impressive.