








Analysis
Among the big Western AI labs, Meta is the odd one out. OpenAI, Google, and Anthropic mostly sell access to closed models behind an API. Meta keeps handing the weights away for free.
That choice is the whole story behind Llama 4. The pitch is simple: if enough developers build on your model, you end up owning the ecosystem, even if you never charge for a single API call. Llama 4 is the latest and largest test of that idea. By the accounts being circulated it landed on 20 April 2026, though Meta's official announcement of the Llama 4 family actually dates to 5 April 2025, so the exact timing here is unconfirmed.
For Australian teams, the practical question isn't who has the biggest model. It's whether an open model you can run, fine-tune, and ship inside your own walls is good enough to skip the per-token bill. Llama 4 is Meta's answer, and the catch is in the licence fine print.
Architecture and Training
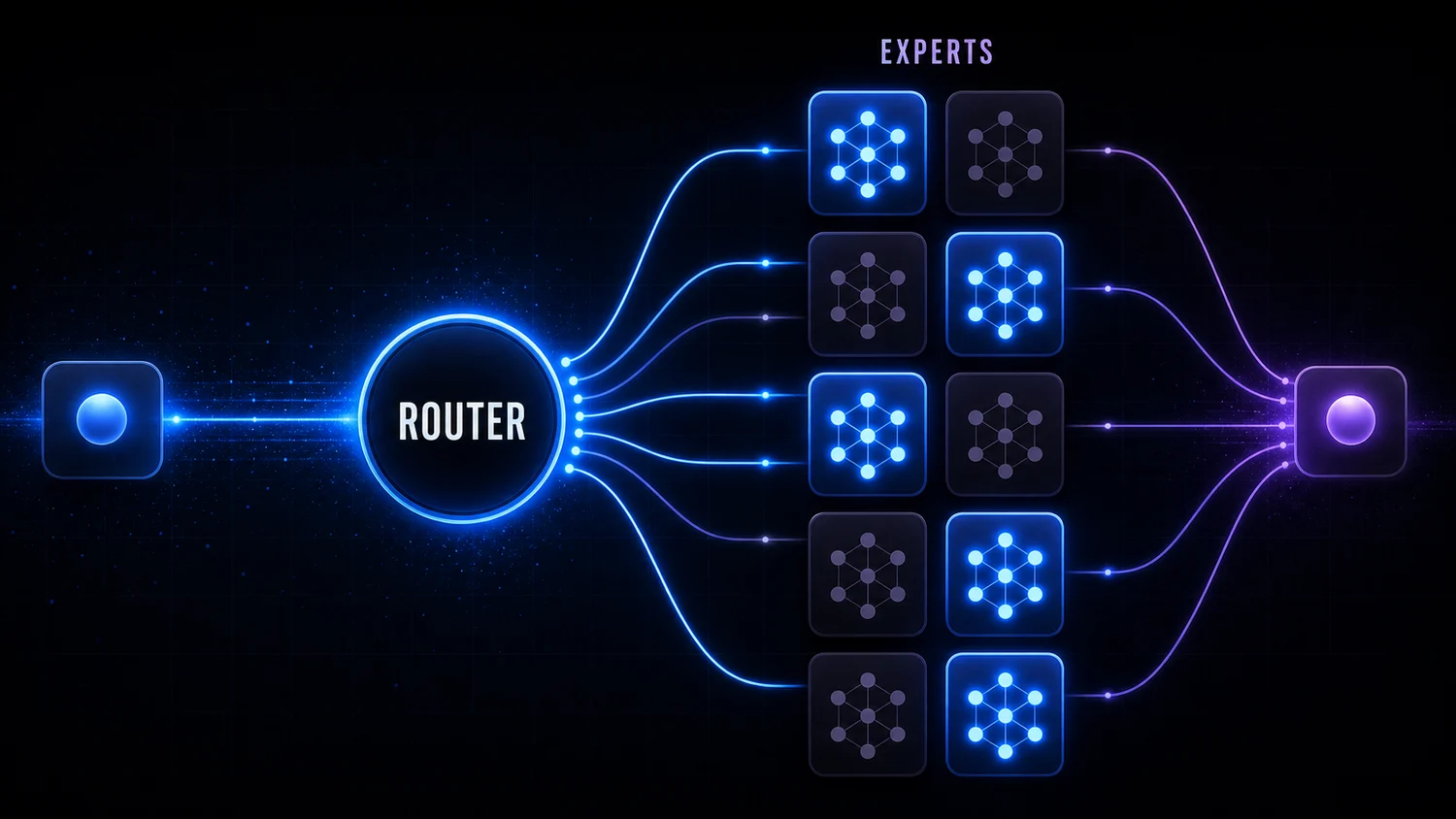
Llama 4 is Meta's first open-weights model to use a Mixture-of-Experts design, a real shift, since Llama 2 and 3 were dense models. The figures being quoted put it at 400 billion total parameters with roughly 45 billion active per token. Worth flagging: those specific numbers don't line up with any confirmed Llama 4 variant (the real 400B model, Maverick, runs about 17B active, and Scout is 109B total), so treat the 45B-active figure as unverified. The general idea holds, though: MoE lets a model punch above the inference cost of a dense model of the same active size, while staying easier to deploy than something like the full 753B-parameter GLM-5.2 from Z.ai.
On training data, the article cites roughly 18 trillion tokens, said to be larger than any earlier Llama model. Meta's own blog actually puts Llama 4 north of 30 trillion tokens, so the 18T figure looks off. The mix reportedly spans web pages, code, books, and a fair amount of multimodal content including images and video transcripts. Meta hasn't published the full breakdown, and a claim that roughly 12% of training tokens are non-textual is unconfirmed, no Meta source states that figure.
The MoE setup uses a learned router that sends each token to the most relevant slice of expert modules. There's a reported routing load balance of 97%, meaning no single expert gets swamped while others idle, but that specific number isn't something Meta has published, so take it as unverified. Whatever the exact figure, balanced routing is the hard part of building one of these models, and it's what keeps inference efficient.
Benchmark Performance
The scores doing the rounds put Llama 4 in mid-tier proprietary territory. MMLU-Pro: 78.5%. HumanEval: 83.7%. MATH: 66.1%. SWE-bench: 55.3%. Be aware these are unconfirmed, Meta's announcement uses comparative language rather than publishing these exact numbers, so the figures appear to be third-party or invented rather than official.
On those numbers, Llama 4 would reportedly sit above DeepSeek V3.5 on most tests, below a Kimi K2.7-Code variant on coding, and behind Claude Opus 4.8 across the board. That comparison is shaky: "DeepSeek V3.5" doesn't appear to exist (DeepSeek's current line is V4), and "Kimi K2.7-Code" is an unconfirmed variant name, though Kimi K2.7 and Claude Opus 4.8 are both real.
The 128,000-token context window cited here is another point to question. Real Llama 4 ships with far more headroom, Scout reportedly offers up to 10 million tokens, so the 128K figure understates what the model actually does. The claim that it trails the 1M-token offerings from MiniMax, DeepSeek, and Google doesn't hold up against that.
The Open-Weights Licence
The licence is where the real debate sits. It allows commercial use, modification, and distribution, but it carries restrictions that have annoyed parts of the open-source community. The headline clause: any company that hits 700 million monthly active users has to request a licence from Meta, granted at Meta's discretion. (The article frames this as automatic "termination"; the real licence frames it as a request requirement, but the 700M threshold is correct.)
The article also claims companies over 100 million monthly active users must request a licence. That one looks invented, the real Llama 4 Community License only has the 700M MAU threshold, with no 100M clause. Either way, the point critics raise stands: a licence with usage gates like this is "source available" with commercial strings, not open source in the classic sense.
Meta's defence is that the gates stop the biggest tech firms from free-riding on its training spend. A quote attributed to Joelle Pineau, described as Meta's VP of AI Research, makes the case at the launch event: "We're investing billions of dollars in training these models. The licence ensures that the largest beneficiaries of open AI are also contributing to its development." Treat this as unverified, the quote couldn't be confirmed, and Pineau in fact left Meta on 30 May 2025, before the article's claimed 2026 launch, so she couldn't have delivered it then.
Strategic Rationale
The logic behind Meta's open bet is plain enough. Meta doesn't sell AI API access as a core business the way OpenAI or Google do. Its money comes from advertising. So AI pays off for Meta by cutting internal costs, sharpening its products, and pulling developers into its orbit. Open-sourcing Llama gives it a talent pipeline, a stack of compatible tools, and a community with a stake in the ecosystem.
The wager is that open AI ends up like open-source software before it, Linux, Android, the web, where openness builds network effects that produce dominant platforms. If Llama becomes the default foundation developers reach for, Meta steers the technology's direction without metering every API call.