
Introduction: Why This One Belongs on the Watchlist
The real shift is the vertical stack Cursor is assembling through Origin, a SpaceX-trained model, and a US$60 billion acquisition. The reason it matters for AI Kick Start readers is practical: this is not just another launch to admire from a distance. It changes how founders, operators, and technical teams should think about agentic coding work over the next few months. The source transcript repeatedly centres on Cursor Composer 2.5, SpaceX, and Origin, with the video framing the topic as a practical workflow rather than a detached product announcement. That is the useful lens. The video is worth treating as implementation intelligence: what should be tested, what should be ignored for now, and what should become part of a repeatable operating system. For Australian small businesses and technical teams, the right question is not "is this impressive?" The right question is "where does this reduce friction without creating a larger governance, security, or maintenance problem?"
What the Video Actually Shows
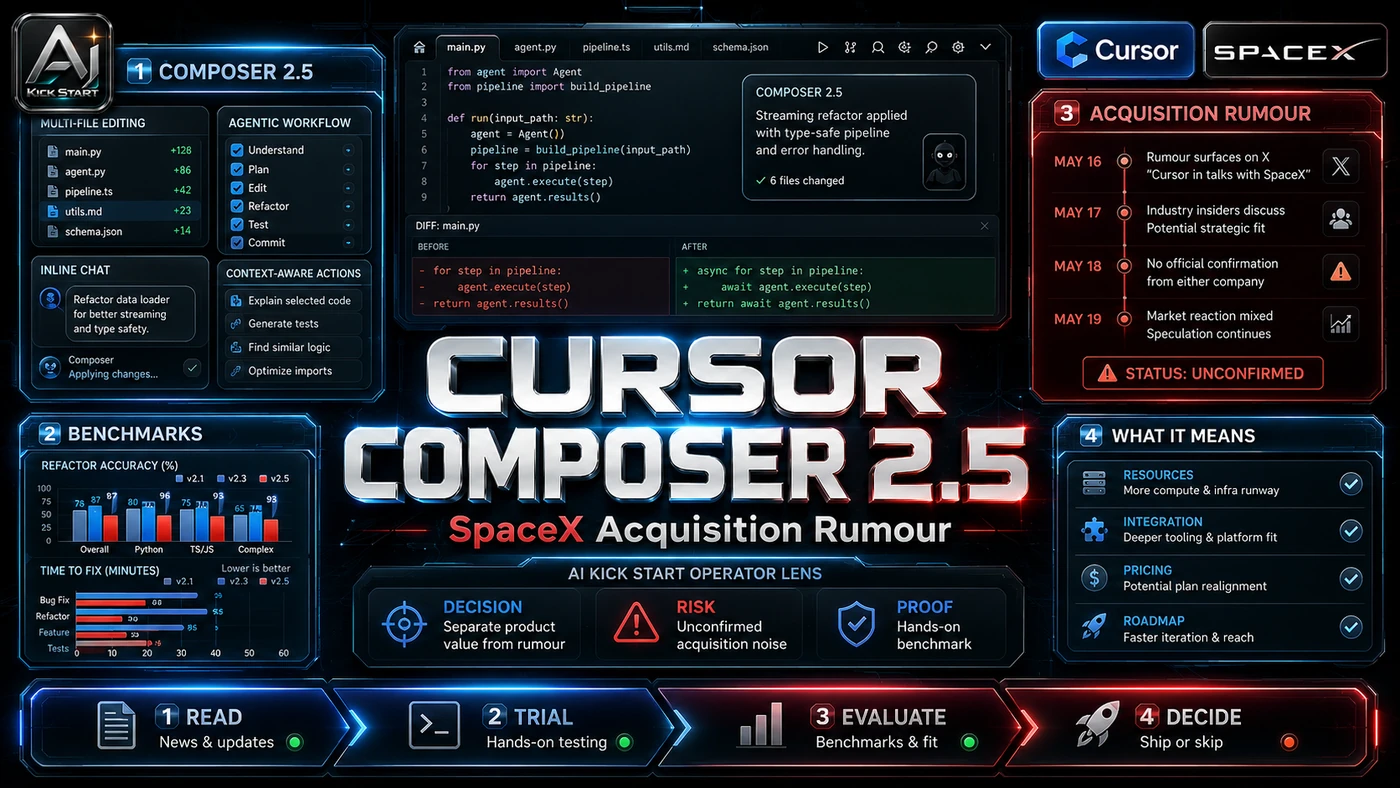
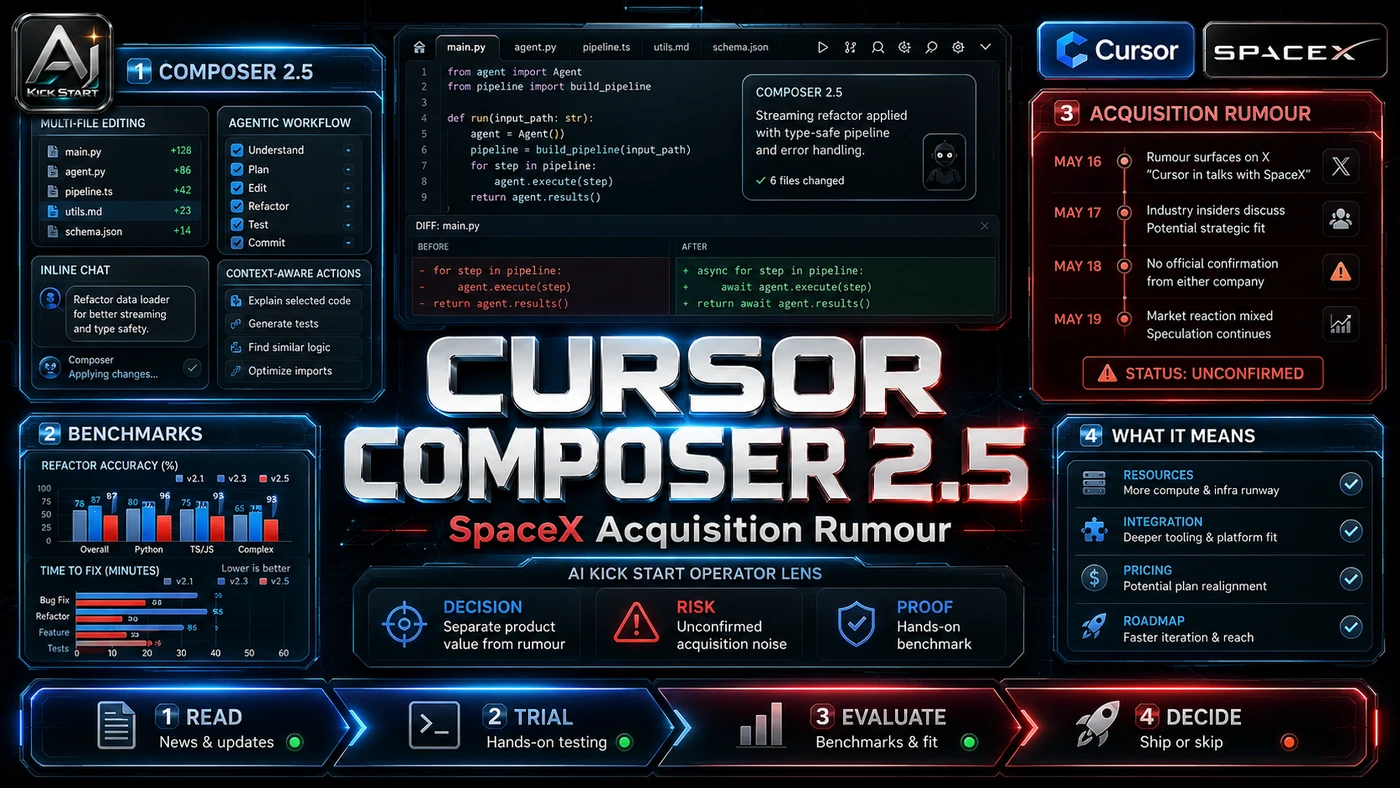
The core pattern is simple: Prompt in natural language inside the Composer panel or chat sidebar, let the agent plan and choose tools, review the diff before accepting, and validate the change through tests and CI. In practice, that means the update sits inside a broader shift from isolated AI prompts to managed systems. A tool, model, or method only becomes valuable when it has clear inputs, a measurable output, a review path, and a way to repeat the result next week. The video's most useful signal is the workflow shape. The moving parts can be summarised as: Prompt Agent plan Diff review CI validation. That is the level at which teams should evaluate it. A demo can be entertaining, but a workflow must survive messy source files, staff handoff, data boundaries, and real deadlines.
The Implementation Pattern
The first implementation lesson is to narrow the scope. Start with one bounded task such as a single bug fix, small refactor, or well-scoped feature branch, and define acceptance criteria and tests before prompting. Broad adoption is usually where AI systems fail first because nobody knows which decision the tool is allowed to make and which decision still belongs to a human. The second lesson is to create a test harness. Build a shared set of standard tasks of known difficulty, run them against Composer 2.5, Claude, and GPT where possible, and measure pass rate, tokens, time to solution, and human corrections. A useful harness does not have to be complicated. It can be a short brief, a fixed sample dataset, a few expected outputs, and one person responsible for judging whether the result is good enough. The third lesson is to capture the process. Document which model to use for which task class, record privacy settings, keep tool permissions small, and add review gates before external messages or write actions. When the process is documented, it can become a reusable skill, checklist, prompt pack, repo pattern, or operating procedure. When it is not documented, the team is back to improvising in chat.
Research Update: What To Correct
This update adds a current-source pass rather than treating the original video summary as enough. The important corrections are the product surface, plan or pricing constraints, and what should be verified before a team depends on the workflow. The SpaceX acquisition is agreed, not closed: as of 23 June 2026, SpaceX announced an agreement to acquire Anysphere for US$60 billion in stock, expected to close in Q3 2026 pending regulatory approval. The 1.5-trillion-parameter model is announced, not benchmarked: Cursor said at Compile 26 it is training a larger model from scratch on over 100,000 GPUs, but no public benchmarks were released. Composer 2.5, built partly on Moonshot AI's open-source Kimi K2.5 base and post-trained by Cursor, is only available inside the Cursor IDE and CLI, not as a standalone API callable from your own CI/CD pipeline or backend. Origin is waitlist-only with a planned fall 2026 launch and undisclosed pricing, described as a Git-compatible host for agentic workflows. Benchmarks are competitive, not dominant: Composer 2.5 scores 79.8% on SWE-Bench Multilingual, 63.2% on CursorBench v3.1, and 69.3% on Terminal-Bench 2.0.
Practical Setup and How-To
The useful next step is a controlled pilot with a named owner, fixed inputs, a measurable output, and a review point. Use the sequence below as the first implementation path before expanding the workflow. Download Cursor from cursor.com and update to the latest build. Open the Composer panel, switch the model to "Composer 2.5" (Fast default, Standard for cost-sensitive work), and review "Privacy Mode" and the stricter legacy zero-retention setting for proprietary work. Start with a bounded task, define acceptance criteria and tests before prompting, run the test suite before accepting any diff, and document outcomes.

Pricing, Access, and Comparison Notes
Pricing and access should be checked at implementation time because AI products change quickly. The safer decision is to compare the tool against the job-to-be-done, not against launch hype. Composer 2.5 has two token tiers: Standard at US$0.50 per million input tokens and US$2.50 per million output tokens, and Fast at US$3.00 per million input tokens and US$15.00 per million output tokens. Claude Opus 4.7 is roughly US$15 per million input tokens and US$75 per million output tokens, with GPT-5.5 in a similar band, so even Fast is cheaper and Standard is roughly one-tenth the cost. Cursor Pro subscriptions include a pool of Composer usage credits, and Teams and Enterprise plans are billed at API rates once included usage is exhausted. The comparison is not purely token price because Claude Code, GitHub Copilot, and Cursor bundle editor integration, model choice, privacy controls, and team management differently, so switching means workflow migration, not just subscription math. Access Plan, preview status, region, account type, admin controls, and rate limits. Cost Subscription, credits, API tokens, retries, hardware, review time, and support burden. Fit Workflow reliability, data handling, output quality, observability, and human approval needs.
Implementation Notes for Teams
For AI Kick Start readers, this is the production filter: keep the first rollout narrow, make the evidence visible, and do not let the tool cross a business boundary until the review model is clear. Start with volunteers on non-critical tasks for two weeks, define allowed use cases such as internal tooling and test generation but not customer-facing authentication or production infrastructure, keep model choice explicit, preserve git hygiene by continuing to use your existing host until Origin is generally available, and never let agents commit directly to protected branches. Review all agent-generated code: read it, test it, and ask why each change was made. Watch the acquisition news closely, because if SpaceX closes the deal and changes data handling, model neutrality, or pricing, you want to know before your next renewal.
Screenshot and Visual Guidance
The second inline image for this article should make the implementation concrete: A clean IDE view showing the Composer 2.5 model picker, a diff panel, the Privacy Mode screen, and a usage dashboard with Composer credit consumption. If the team is documenting a real rollout, capture setup screens, before/after outputs, permission settings, cost meters, and review evidence rather than decorative screenshots.
Where It Fits for Real Teams
For founders, the opportunity is speed with evidence. Composer 2.5 can reduce time to first useful output and cut API spend, but it should still produce inspectable artefacts. For operators, the value is consistency. If the same task is done slightly differently every time, AI can either make the inconsistency worse or help standardise the path, and the difference is whether the workflow has rules, examples, and review checkpoints. For technical teams, the value is leverage. A strong setup lets agents take on repeatable work while engineers keep control over architecture, security, deployment, and final judgement. The practical fit is strongest when the task has clear source material, a known output format, and a low-cost way to verify quality. It is weaker when the task is vague, politically sensitive, legally risky, or dependent on facts that cannot be checked.
Trade-offs and Risks
The main risk is data custody. The SpaceX acquisition could change retention policies, audit commitments, and data residency assurances, so if you handle regulated data or customer PII you must verify the current policy and re-verify after the acquisition closes. That risk can be managed, but only if it is named before the workflow becomes normal. A second risk is vendor lock-in and model neutrality loss. AI systems often look better in a screen recording than they feel inside a production workflow. The test is whether the result is repeatable when the source material changes, the operator changes, and the deadline is real. Origin, the proprietary model, and Cursor Mobile point toward a fully verticalised stack that reduces contract leverage and increases switching cost, and SpaceX has not committed to preserving access to Anthropic and OpenAI models after the deal closes. A third risk is agentic overreach and unverified future claims. Cheaper tokens can encourage longer sessions and weaker review gates, while the 1.5-trillion-parameter model and Origin are not available to evaluate, so do not build a migration plan around them until you can test them. This is why AI Kick Start generally recommends a staged rollout: sandbox first, internal use second, customer-facing deployment last.
The Next Sensible Test
The next sensible test is a small controlled implementation. Pick one workflow, one owner, one expected output, and one acceptance check. Run it twice. If the second run is easier than the first, the pattern is worth keeping. Do not judge the workflow by the best possible demo. Judge it by the worst acceptable production case. Ask: what happens when the source file is incomplete, the tool is unavailable, the output is wrong, or a staff member needs to explain the result to a customer? If those answers are clear, this belongs in the roadmap. If they are not, it belongs in the lab until the operating model catches up.


