









Best model for coding: SWE-bench Pro leaderboard
Analysis
A new coding model lands almost every week now, each one claiming to be the best your money can buy. For a business deciding what to put in front of its developers, that noise is the problem. You need one number that says how well a model actually does the job.
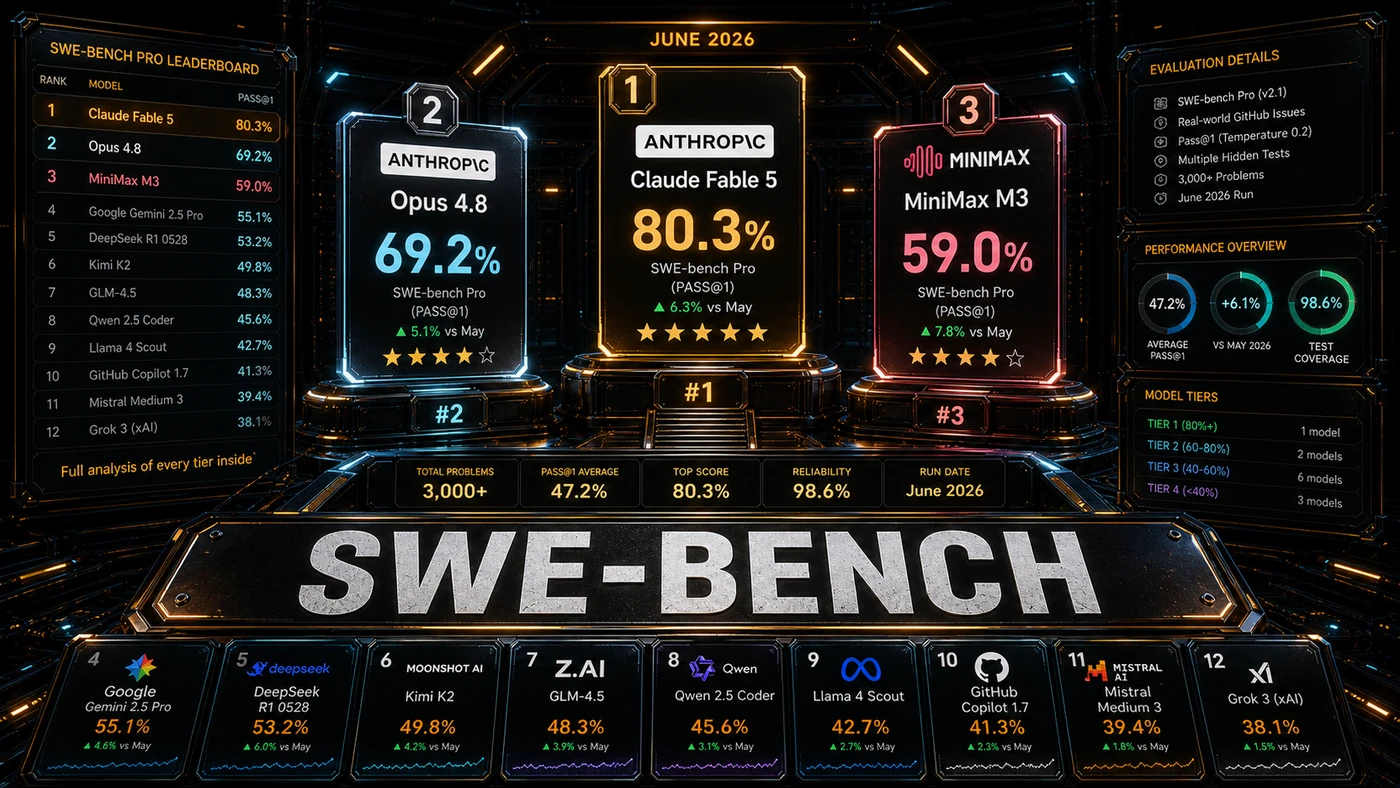
SWE-bench Pro is meant to be that number. It throws real GitHub issues at a model, fix this bug, build this feature, write these tests, and checks whether the change works. So when the June 2026 results came out, the headline was simple: Anthropic's Opus 4.8 leads the field of models you can buy, at 69.2%. The model that beat it, Claude Fable 5, was pulled offline under a US export-control directive days after launch, which leaves Opus as the practical top pick.
Here is the part the headline skips. The leaderboard stacks two kinds of scores in one column. Some are measured by an independent lab running every model through the same harness. Others are the figures vendors report from their own tuned setups. The gap between the two can run 10 to 30 points, so a straight rank-by-rank read of the table flatters some models and shortchanges others. Worth keeping in mind before you sign anything.
What follows is the full table, the tier-by-tier breakdown, and where the numbers are solid versus where they need a pinch of salt.
The June 2026 leaderboard
The scores below come from the article's source table. Some are independently measured; several are vendor-reported or could not be confirmed against independent leaderboards, and we flag those as we go.
| Rank | Model | SWE-bench Pro | MMLU | Price (In/Out) | Licence |
|---|---|---|---|---|---|
| 1 | Claude Fable 5 | 80.3% | 92.1% | $10.00 / $50.00 | Closed (SUSPENDED) |
| 2 | Claude Opus 4.8 | 69.2% | 89.8% | $5.00 / $25.00 | Closed |
| 3 | Claude Opus 4.7 | 63.8% | 89.2% | $5.00 / $25.00 | Closed |
| 4 | GPT-5.5 Pro | 62.4% | 89.7% | $8.00 / $40.00 | Closed |
| 5 | MiniMax M3 | 59.0% | 86.4% | $0.30 / $1.20 | Open |
| 6 | GPT-5.5 | 58.6% | 88.4% | $5.00 / $30.00 | Closed |
| 7 | Claude Sonnet 4.6 | 58.1% | 87.6% | $3.00 / $15.00 | Closed |
| 8 | Kimi K2.7-Code | 56.8% | 85.7% | $0.50 / $2.00 | Open |
| 9 | Grok 4 | 54.8% | 87.2% | $5.00 / $25.00 | Closed |
| 10 | Gemini 3.1 Pro | 54.2% | 88.1% | $3.50 / $10.50 | Closed |
| 11 | DeepSeek V3.5 | 52.4% | 85.8% | $0.15 / $0.60 | Open |
| 12 | GLM-5.2 | 51.4% | 85.2% | $0.80 / $2.40 | Open |
| 13 | Llama 4 | 50.2% | 84.8% | Free | Open |
| 14 | Mistral Large 2 | 48.6% | 85.1% | $2.00 / $6.00 | Open |
| 15 | Gemini 3.5 Flash | 48.2% | 86.8% | $0.35 / $0.70 | Closed |
| 16 | Qwen 3 | 46.2% | 84.6% | $0.40 / $1.20 | Open |
| 17 | GPT-5.5 Instant | 42.1% | 84.2% | $0.50 / $1.50 | Closed |
A word on what this benchmark is before you read too much into the column. SWE-bench Pro is a large set of real engineering tasks, roughly 1,865 of them, pulled from 41 professional repositories, covering bug fixes, feature work, test generation, and code review. The public set deliberately uses GPL-licensed code to make it harder for a model to have memorised the answers during training. A high score points to a model that can act as a working engineering assistant, not just spit out snippets.
One thing the table does not show on its face: the figures blend two measurement styles. Vendor-tuned numbers (Fable 5's 80.3%, Opus 4.8's 69.2%) sit next to standardised ones, and on independent trackers the best apples-to-apples score as of mid-June 2026 was closer to 59%. Read the ranking as a rough guide, not gospel.
Tier 1: The elite (65%+)
One available model clears 65%: Claude Opus 4.8 at 69.2%. Anthropic released it on 28 May 2026 as its strongest coding model, with the Pro score climbing from the prior 64.3% (the table lists Opus 4.7 at a slightly lower 63.8%). This is the one to reach for on work that cannot afford mistakes, heavy refactoring, modernising legacy code, architectural changes. Fable 5's reported 80.3% would have owned this tier, but it was globally suspended on 12 June 2026 under an export-control directive, and that score is vendor-reported and contested in any case. For now, Opus 4.8 is the real pick.
Tier 2: The capable (55-65%)
This is the workhorse band. GPT-5.5 Pro (a reported 62.4%), MiniMax M3 (59.0%), GPT-5.5 (58.6%), Sonnet 4.6 (58.1%), and Kimi K2.7-Code (a reported 56.8%) cover most engineering tasks dependably.
Two of those numbers come with caveats. The GPT-5.5 Pro line in the table, 62.4% at $8/$40, does not hold up: OpenAI's actual GPT-5.5 Pro pricing is closer to $30/$180, and the standard GPT-5.5 sits at 58.6%, so treat the Pro figure as unconfirmed. Kimi K2.7-Code's 56.8% is also shaky, no independent SWE-bench Pro number exists for K2.7 yet (the 58.6% often quoted belongs to the older K2.6), and its real pricing looks more like $0.95/$4.00.
The standout here is MiniMax M3. Open weights, a 1M-token context window, and a verified 59.0% on SWE-bench Pro at $0.30/$1.20, it beats GPT-5.5 and Gemini 3.1 Pro on this benchmark for a fraction of the cost. GPT-5.5's 58.6% at $5/$30 is also a confirmed figure. Sonnet 4.6's 58.1% could not be confirmed on independent boards, so take it as indicative.
Tier 3: The competent (45-55%)
These models do routine coding fine but lose the thread on harder problems: Grok 4 (54.8%), Gemini 3.1 Pro (54.2%), DeepSeek V3.5 (52.4%), GLM-5.2 (51.4%), Llama 4 (50.2%), Mistral Large 2 (48.6%), and Gemini 3.5 Flash (48.2%). DeepSeek V3.5 and Llama 4 are the value plays in the band.
Several of these figures are worth questioning. Gemini 3.1 Pro's 54.2% runs ahead of the ~46.1% reported under a standardised harness. GLM-5.2 looks understated, Zhipu's model is the top open-source entry on the llm-stats board at 62.1%, well above the 51.4% here, and on that board it actually outranks MiniMax M3, which flips the article's ordering. The Grok 4, DeepSeek V3.5, Llama 4, Mistral Large 2, and Gemini 3.5 Flash scores could not be corroborated on the independent leaderboards we checked, so read them as unconfirmed. DeepSeek may also be a generation behind, mid-2026 sources point to DeepSeek V4/V4-Pro as the current release rather than V3.5.
Tier 4: The assistants (<45%)
Qwen 3 (46.2%) and GPT-5.5 Instant (42.1%) suit code explanation, simple scripts, and boilerplate. Don't lean on them for production engineering. Both scores are unconfirmed against independent SWE-bench Pro boards, which is reason enough on its own to keep them out of critical work.
Recommendations by use case
- Mission-critical coding: Opus 4.8 (69.2%, verified)
- Best open-weights coding: MiniMax M3 (59.0%, verified), though GLM-5.2 may edge it out on independent boards
- Best value coding: DeepSeek V3.5 (a reported 52.4% at $0.15/$0.60; score unconfirmed)
- Best free coding: Llama 4 (a reported 50.2%; score unconfirmed)
- Enterprise with OpenAI: GPT-5.5 (58.6%, verified; the GPT-5.5 Pro line in the table is unreliable)
- Speed-sensitive coding: Sonnet 4.6 (a reported 58.1%, fast; score unconfirmed)
Verdict
The coding-model market is crowded, and that is good news for buyers. Opus 4.8 leads on raw capability among models you can use, MiniMax M3 makes a strong case on open weights (with GLM-5.2 close behind on the independent board), and the cheaper open models cover most day-to-day work.
Pick on your real constraints, budget, data privacy, which ecosystem you're already in. But do it with eyes open: the table mixes vendor-tuned and independently measured scores, and a few of the lower-tier entries could not be confirmed at all. Use the leaderboard to narrow the shortlist, then test your top two or three against your own codebase before you commit. The benchmark tells you who's in the running; your repository tells you who wins.